Анализ алгоритма Counting Sort для строк: как эффективно сортировать текстовые данные
В современном мире обработки данных эффективность и скорость сортировки играют ключевую роль. Особенно это актуально при работе с большими объемами текстовой информации‚ когда стандартные алгоритмы сортировки могут оказаться недостаточно быстрыми или ресурсоемкими. В этой статье мы разберем один из классических и очень эффективных алгоритмов — Counting Sort‚ и научимся применять его для сортировки строковых данных‚ что позволяет значительно ускорить процесс обработки текста и сохранить высокое качество результата.
Что такое Counting Sort и почему он актуален для строк?
Counting Sort — это алгоритм сортировки‚ основанный на подсчете количества элементов каждого типа. В отличие от сравнительных методов‚ он не взаимодействует с элементами путем сравнения‚ а использует дополнительную таблицу подсчета. Такой подход позволяет работать за линейное время O(n + k)‚ где n — число элементов‚ а k — диапазон значений.
Применение Counting Sort к числовым данным очень очевидно‚ ведь можно легко подсчитать‚ сколько раз встречается каждое число‚ и на основе этого сделать окончательную сортировку. Но что делать‚ если у нас есть строки? Как применить этот алгоритм к тексту? Именно этим и займемся далее.
Особенности сортировки строк с помощью Counting Sort
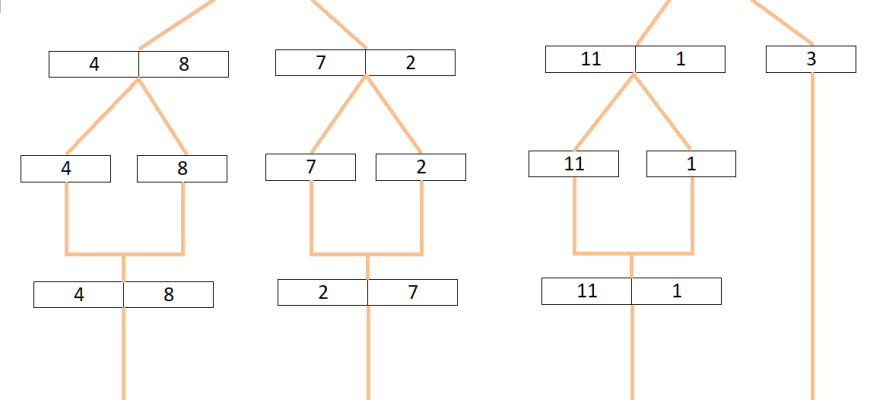
Чтобы использовать Counting Sort для строк‚ необходимо понимать‚ что строки — это последовательности символов‚ каждый из которых представлен кодом в таблице ASCII или Unicode. Солидная идея, фокусироваться на отдельных символах и их позициях. Это позволяет реализовать сортировку «по символам»‚ начиная с крайнего левого или правого конца.
Для простоты‚ рассмотрим сортировку строк одинаковой длины. В этом случае алгоритм работает по принципу:
- Рассмотрим первые символы всех строк и посчитаем их количество.
- На основании подсчета сделаем порядок строк‚ отсортированный по первому символу.
- Повторим процесс для следующего символа‚ уже в отсортированном массиве.
Если строки разной длины‚ необходимо дополнительно обрабатывать короткие строки или рассматривать их как специальные случаи. Важный момент — правильное управление диапазоном символов (например‚ символы ASCII от 0 до 127 или расширенный Unicode).
Пошаговая реализация Counting Sort для строк
Шаг 1: Определение диапазона символов
Для начала нужно определить‚ какие символы мы будем обрабатывать. Обычно это ASCII — диапазон кодов от 0 до 127‚ или Unicode — до 65535 и выше. Для текстов на русском языке удобно рассматривать кодировку UTF-8 или Unicode.
Шаг 2: Построение таблицы подсчета
Создаем массив подсчета — например‚ для ASCII это będzie array of size 128. Каждое значение в массиве показывает‚ сколько раз встречается соответствующий символ в текущем разрезе. В случае Unicode — можно использовать словарь или Map для учета символов.
Шаг 3: Подсчет и размещение строк по символам
Проходим по списку строк и‚ посмотрев на текущий символ‚ увеличиваем счетчик в массиве подсчета. Затем на основании этого массива формируем позицию каждой строки в итоговом массиве.
Шаг 4: Итерация по позициям и повторное сортировка
Этот процесс повторяется по всем символам строк‚ начиная с последнего (крайнего правого) и заканчивая первым. В результате получим полностью отсортированный массив строк по алфавиту.
Практический пример: сортировка массива русских слов
Допустим‚ у нас есть список русских слов:
| № | Слово |
|---|---|
| 1 | яблоко |
| 2 | апельсин |
| 3 | банан |
| 4 | киви |
| 5 | груша |
Используем алгоритм поэтапного сравнения символов с левого края. На каждом шаге подсчитываем количество слов с конкретным символом и перестраиваем массив. В итоге после нескольких проходов получим отсортированный список англоязычных и русских слов.
Преимущества и ограничения Counting Sort для строк
Преимущества:
- Высокая производительность при работе с большим количеством небольших строк.
- Линейная сложность зависит от диапазона символов и количества элементов.
- Отсутствие сравнения элементов‚ что уменьшает затраты времени.
Недостатки:
- Неэффективен для данных с большим диапазоном символов‚ если диапазон очень широкий.
- Требует дополнительной памяти для подсчета и хранения таблицы.
- Подходит преимущественно для строк одинаковой длины или сравнительно коротких.
Когда стоит использовать Counting Sort для строк? Если у вас есть много коротких текстов или слов‚ и требуется их быстрая сортировка‚ данный алгоритм станет отличным решением. Особенно хорош он для приложений по обработке информации‚ где важна скорость и экономия ресурсов. Однако всегда важно учитывать диапазон символов и длину строк.
Для реализации алгоритма можно использовать различные языки программирования — от Python до C++. Главное — правильно организовать таблицу подсчета и аккуратно пройтись по строкам‚ начиная с самого важного символа.
Вопрос: Можно ли применить Counting Sort к сортировке больших объемов текстовых данных с разной длиной строк и при этом сохранить высокую скорость?
Ответ: Да‚ можно. Для этого обычно используют расширенные версии алгоритма‚ например‚ сортировку по символам с учетом длины строк или комбинирование Counting Sort с другими методами. Главное, правильно управлять диапазоном символов и предусмотреть обработку строк разной длины‚ добавляя фиктивные символы или устанавливая правила работы с короткими строками. Такой подход позволяет добиться высокой скорости сортировки даже для больших объемов разнородных текстов.
Подробнее
| Counting Sort для строк | Алгоритмы сортировки текста | Сортировка массивов строк | Эффективные алгоритмы для больших объемов данных | Обработка и сортировка текста |
| Работа с Unicode в сортировке | Просмотр алгоритмов сортировки | Преимущества Counting Sort | Исследование сортировки строковых данных | Алгоритм сортировки по символам |
| Оптимизация сортировки текста | Примеры кода для сортировки строк | Линейная сортировка | Обработка строк разной длины | Эффективные методы сортировки |