Анализ использования кэша в алгоритмах сортировки: секрет скорости и эффективности
В современном мире обработки данных скорость выполнения алгоритмов играет ключевую роль. Особенно это касается алгоритмов сортировки‚ которые являются фундаментальными при работе с большими объемами информации. Но мало кто задумывается о том‚ как именно использование кэша влияет на производительность этих алгоритмов. Именно этот аспект становится предметом нашего глубокого анализа.
Мы расскажем о том‚ как кэш-память встроена в компьютерное оборудование‚ почему её эффективность критична для быстродействия программ‚ и какие особенности имеются у популярных алгоритмов сортировки с точки зрения их использования кэша. Наш разговор пойдет о принципах работы кэша‚ специфике доступа к данным во время сортировки и как правильно настраивать алгоритмы для максимальной скорости.
Что такое кэш-память и почему она важна?
Перед тем как углубляться в особенности алгоритмов сортировки‚ стоит понять основное — что такое кэш-память и как она работает. Кэш — это небольшая‚ очень быстрая память‚ расположенная внутри процессора‚ предназначенная для быстрого хранения данных‚ к которым процессор обращается чаще всего. Благодаря кэшу операционная система и программы избегают долгих обращений к основной памяти‚ которая значительно медленнее.
Различают уровни кэша: L1‚ L2‚ L3.
Каждый из них отличается размером‚ скоростью и степенью хранения данных:
| Уровень кэша | Объем | Скорость доступа | Особенности |
|---|---|---|---|
| L1 | от 32 до 64 КБ | самая высокая | находится внутри ядра процессора‚ очень быстрый |
| L2 | от 256 КБ до 1 МБ | быстрее‚ чем L3 | отдельная для каждого ядра или объединена |
| L3 | от 2 до 16 МБ | медленнее‚ чем L1 и L2 | общая для всех ядер |
Основная идея — если данные находятся в кэше‚ они получаются в разы быстрее‚ чем при обращении к основной памяти. Поэтому важно понять‚ как алгоритмы используют память‚ и каким образом это влияет на их эффективность.
Связь между кэш-памятью и алгоритмами сортировки
Рассмотрим‚ как алгоритмы сортировки взаимодействуют с памятью компьютера. В большинстве случаев они работают с большими массивами данных. Если в процессе сортировки происходит множество случайных обращений к разным частям памяти‚ кэш скорее всего будет часто "переходить" из используемых данных в неиспользуемые.
Анализируя это‚ мы можем выделить несколько ключевых аспектов:
- Локальность данных: алгоритмы с хорошей временной локальностью (локальностью по времени) используют ту же часть памяти несколько раз за короткое время‚ что хорошо для кэша.
- Локальность пространства: при последовательных обращениях к элементам массива‚ данные загружаются в кэш более эффективно.
- Проходы по данным: чем большее количество обращений к памяти‚ тем выше вероятность "промахов" кэша (cache misses).
Теперь конкретнее о том‚ как разные алгоритмы сортировки используют эти особенности.
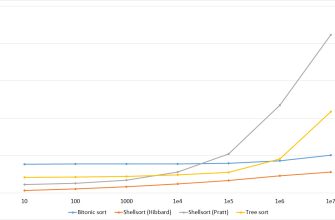
Наиболее популярные алгоритмы сортировки и использование кэша
Рассмотрим основные алгоритмы сортировки‚ обращая особое внимание на их работу с памятью:
- Пузырьковая сортировка (Bubble Sort)
- Сортировка вставками (Insertion Sort)
- Быстрая сортировка (Quick Sort)
- Сортировка слиянием (Merge Sort)
- Тим сортировка (Timsort)
Несложный‚ но очень медленный алгоритм. Он осуществляет много проходов по массиву‚ сравнивая и меняя местами соседние элементы. Благодаря многочисленным обменам элементов‚ зачастую данные перехватываются и передаются с большой вероятностью в кэш и out of cache (промахи)‚ что делает его неэффективным на больших объемах.
Работает эффективно на почти отсортированных массивах. Использует локальность по времени‚ поскольку обращается к соседним элементам‚ что способствует хорошей использованию кэша.
Один из самых быстрых алгоритмов целом. В среднем‚ при правильной реализации‚ он использует рекурсивные проходы по разделам массива‚ что позволяет элементам оставаться в кэше на длительное время и уменьшает число промахов кэша.
Стек рекурсивных вызовов и последовательное слияние в основном работают с массивами‚ разбитыми на части. Эффективна при правильной организации памяти и использовании блюстак (аккумулятора для временных данных)‚ что также способствует хорошей локальности и использованию кэша.
Комбинация сортировок вставками и слиянием‚ специально разработанная для повышенной локальности данных и максимальной эффективности на реальных данных.
Практические рекомендации по улучшению использования кэша при сортировке
Чтобы максимально эффективно использовать кэш при реализации сортировок‚ мы советуем учитывать следующие принципы:
- Работайте с последовательными данными. Передача массива целиком — один из лучших способов уменьшить промахи кэша.
- Минимизируйте случайный доступ. Избегайте часто обращаться к случайным элементам массива вне актуальных разделов или блоков.
- Используйте алгоритмы‚ локальные по времени. Такие как сортировка вставками для небольших наборов данных.
- Оптимизируйте деление массива. В быстрых алгоритмах разделение массива помогает уменьшить количество обращений к памяти.
Особенно важно учитывать‚ что современные процессоры и архитектуры могут иметь разные особенности касательно размера кэша‚ и подстроиться под конкретное оборудование даст существенный прирост к скорости.
Анализируя использование кэша в алгоритмах сортировки‚ мы приходим к мысли‚ что эффективность выполнения напрямую зависит от того‚ насколько умело мы можем "уместить" данные в кэш-память. Чем менее "случайным" является доступ к элементам‚ чем лучше реализована локальность‚ тем быстрее алгоритм работает‚ и тем Lower ЛИТР промахов кэша.
Это особенно важно при проектировании собственных реализаций‚ оптимизаций и работы с big data. Осознание того‚ как именно процессор обрабатывает память‚ дает возможность писать более эффективный код‚ уменьшать время выполнения и потребление ресурсов.
Вопрос-ответ
Вопрос: Почему одни алгоритмы сортировки работают быстрее именно на определенных данных‚ а другие — нет?
Ответ заключается в том‚ что эффективность алгоритма зависит от его способности использовать память и кэш. Алгоритмы‚ которые лучше используют локальность данных‚ особенно при последовательных обращениях и меньшей переработке элементов‚ работают значительно быстрее. Например‚ сортировка слиянием или быстрая сортировка при правильно организованной реализации лучше используют кэш‚ в то время как пузырьковая сортировка страдает от большого количества случайных обращений к памяти‚ что вызывает промахи кэша и медленную работу.
Подробнее
| ключевые особенности кэш | эффективность алгоритмов сортировки | локальность данных | скорость работы алгоритмов | настройка кэша программистом |
| использование кэша в sorting | оптимизация кэша при сортировке | локальность данных | сравнительная скорость | уровни кэша |
| память кэша и производительность | алгоритмы сортировки и кэш | локость по времени | оптимизация доступа к памяти | настройки для ускорения |
| использование массива и кэш | стратегии уменьшения промахов | локальность по пространству | эффективные подходы | профилирование и оптимизация |
| самые быстрые сортировки и кэш | использование локальности | уровни кэш и их особенность | влияние алгоритмов на скорость | лучшие практики |
| советы по оптимизации сортировки | проблемы промахов кэша | компьютерная архитектура | ускорение обработки | эффективность кэш-памяти |