Анализ наихудшего случая для быстрой сортировки: что нужно знать каждому разработчику
Когда речь заходит о сортировке данных, одним из наиболее популярных и эффективных алгоритмов в практике является быстрая сортировка․ Она широко используется благодаря своей скорости и относительно низкому расходу ресурсов․ Однако, несмотря на свою эффективность в большинстве случаев, быстрая сортировка обладает и значительными недостатками, особенно в наихудших ситуациях, которые могут значительно замедлить работу алгоритма․ В этой статье мы подробно разберем, что представляет собой наихудший случай для быстрой сортировки, почему он происходит и как его избежать или минимизировать․
Что такое быстрая сортировка и как она работает?
Перед тем как углубиться в анализ наихудших сценариев, нужно понять принципы работы самого алгоритма․ Быстрая сортировка, это стратегия divide-and-conquer, то есть разделяй и властвуй․ Ее суть заключается в следующем:
- Выбирается опорный элемент, или "пивот"․
- Массив разделяется на две части: элементы, меньшие пивота, и элементы, большие или равные ему․
- Для каждой из полученных частей рекурсивно применяется тот же алгоритм․
На практике выбор пивота и порядок разделения имеют большое значение для эффективности․ Хороший выбор пивота обеспечивает сбалансированное разделение массива и быстрое выполнение сортировки, в то время как плохой — приводит к глубоким рекурсиям и затягиванию времени выполнения․
Что такое наихудший случай при быстрой сортировке?
Наихудший случай для быстрой сортировки — это ситуация, когда алгоритм демонстрирует свою наименьшую эффективность․ Обычно он происходит, когда выбранный пивот не позволяет разбивать массив на приблизительно равные части, а вместо этого создает очень неравномерные разделы․ Это классическая ситуация, которая приводит к максимальной глубине рекурсии и, соответственно, к увеличению времени работы․
Именно такой сценарий возникает, когда, например, массив уже отсортирован или практически отсортирован, а алгоритм выбирает пивот как первый или последний элемент․ Тогда каждый раз разделение происходит очень неудачно — один из подмассивов почти такой же длины, как исходный, что ведет к цепочке рекурсий длиной в N․
Почему важен анализ наихудшего случая?
- Понимание слабых сторон: Знание, когда алгоритм работает менее эффективно, помогает проектировать более устойчивые системы․
- Оптимизация сценариев использования: Можно принимать меры, чтобы избежать таких ситуаций или снизить их влияние․
- Выбор правильных методов: В сложных случаях лучше знать альтернативные алгоритмы․
Механизмы формирования наихудших сценариев
Определение наихудшего сценария для быстрой сортировки связано с особенностями выбранного элемента-разделителя (пивота) и исходных данных․ Рассмотрим подробнее причины возникновения худших случаев:
Уже отсортированные или почти отсортированные массивы
Этот случай — один из самых распространенных․ Когда массив уже отсортирован, а алгоритм выбирает крайний элемент как пивот, разделение происходит неэффективно, и глубина рекурсии увеличивается․
Выбор плохого пивота
Например, всегда выбирать первый или последний элемент как пивот — неудачно, если массив уже отсортирован или частично отсортирован․ В таких случаях разбиения не будут сбалансированными, и эффективность ухудшится․
Входные данные со специфической структурой
Некоторые случаи могут быть специально подготовленными данными, где структура входных данных способствует формированию максимально однородных разделов, вызывая рекурсивное деление массива в один элемент за раз․
Асимптотическая сложность и что она показывает?
| Сценарий | Сложность | Описание |
|---|---|---|
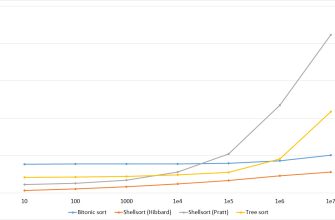
| Лучший случай | O(n log n) | Массив разбит на две примерно равные части на каждом шаге |
| Средний случай | O(n log n) | Обработка массивов со случайной структурой данных |
| Худший случай | O(n^2) | Неудачный выбор пивота, массив частично или полностью отсортирован |
Из таблицы видно, что в худшем случае сложность вырастает до квадратичной, что существенно превышает среднюю эффективность․
Как избежать наихудших сценариев?
Чтобы минимизировать риск возникновения худших случаев, существует несколько практических подходов:
- Использование стратегии выбора пивота: Например, случайный выбор элемента или медиана трех — это хорошие методы для балансировки разбиений․
- Внедрение гибридных алгоритмов: В некоторых случаях рекомендуется использовать гибридные подходы, например, быструю сортировку с переходом на сортировку слиянием при глубоком рекурсивном уровне․
- Предварительная обработка данных: Обнаружение и преобразование входных данных для избежания заранее подготовленных худших сценариев․
Практическая реализация, рекомендации
Если вы работаете с большими массивами или входными данными, склонными к структурированию, будьте осторожны с выбором стратегии сортировки․ Используйте:
- Медиану трех: Выбор опорного элемента как медианы трех случайных элементов․
- Интерактивные алгоритмы: Автоматическая адаптация метода сортировки в зависимости от структуры данных․
Понимание и анализ наихудших случаев играет важную роль в разработке стабильных и надежных алгоритмов․ В контексте быстрой сортировки важно помнить, что:
- Всегда существует риск возникновения наихудшего сценария, особенно при неаккуратных или предсказуемых данных․
- Эффективное управление выбором пивота и использование гибридных методов значительно снижают вероятность этого․
- Подготовка к худшим ситуациям — это ключ к созданию устойчивых решений в области обработки больших данных․
Обладая знаниями о механизмах формирования и избегания наихудших сценариев, мы можем значительно повысить эффективность своих алгоритмов и обеспечить стабильную работу даже в самых сложных условиях․
Вопрос-Ответ
Почему именно сортировка уже отсортированных данных считается худшим сценарием для быстрой сортировки?
Потому что при использовании простого выбора опорного элемента, например, первого или последнего в качестве пивота, алгоритм не сможет разбивать массив на равные части․ Если массив уже отсортирован, то каждый раз разделение даст очень незначительное уменьшение — что заставляет рекурсию глубоко уходить в каждую итерацию, тем самым увеличивая общую сложность до квадратичной, O(n^2)․ Такое поведение значительно снижает эффективность быстрой сортировки в случаях, когда данные изначально подготовлены или имеют предсказуемую структуру․
Подробнее
| № | Запрос | Тип | Описание | Тематика |
|---|---|---|---|---|
| 1 | быстрая сортировка худший случай | LSI запрос | Обзор ситуации, при которой алгоритм работает максимально медленно | Алгоритмы и структуры данных |
| 2 | как выбрать лучший пивот для быстрой сортировки | LSI запрос | Советы по выбору опорного элемента для оптимизации работы алгоритма | Оптимизация алгоритмов |