Блочная сортировка: Как эффективно организовать распределённые системы для обработки данных
В современном мире объем данных растет с каждым днем, а необходимость их быстрого и качественного анализа становится все более актуальной. Одним из эффективных методов обработки больших массивов информации являеться блочная сортировка. Именно она помогает системам распределять и упорядочивать данные так, чтобы максимизировать производительность и снизить затраты времени. В этой статье мы расскажем о принципах работы блочной сортировки, её особенностях, а также о том, как её применяют в реальных распределенных системах. Мы поделимся нашим опытом и предложим практические рекомендации для тех, кто хочет внедрить данный алгоритм в свои проекты.
Что такое блочная сортировка и почему она важна?
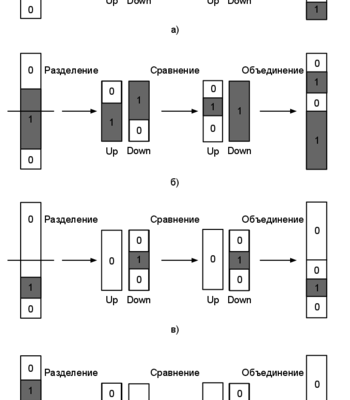
Блочная сортировка — это алгоритм сортировки, который разделяет исходные данные на несколько блоков, каждый из которых затем сортируется отдельно. После этого происходит слияние отсортированных блоков, что в итоге дает полностью отсортированный массив. Такой подход особенно эффективен при работе с большими объемами данных, поскольку позволяет обрабатывать их параллельно, за счет чего снижается время выполнения и увеличивается масштабируемость системы.
Внутри распределенных систем блочная сортировка помогает:
- Обеспечить баланс нагрузки — разные узлы системы могут одновременно сортировать отдельные блоки.
- Уменьшить время обработки — параллельное выполнение ускоряет весь процесс.
- Обеспечить масштабируемость — при росте данных расширение системы не требует полного перепроектирования алгоритма.
Использование блочной сортировки особенно актуально в ситуациях, когда объем данных превышает возможности одного устройства или сервера.
Основные этапы блочной сортировки
Этот алгоритм можно разбить на несколько ключевых этапов, каждый из которых критически важен для конечного результата:
- Разделение данных на блоки
- Локальная сортировка внутри каждого блока
- Объединение отсортированных блоков
- Финальное слияние и корректировка порядка
Давайте подробнее рассмотрим каждый этап:
Разделение данных
На этом этапе мы разбиваем исходный массив или поток данных на равные по размеру блоки. Размер блока зависит от объема оперативной памяти и характеристик системы.
| Количество блоков | Размер каждого блока | Общий объем данных |
|---|---|---|
| n | m | n * m |
Локальная сортировка
Каждый блок сортируется независимо внутри своей области, что значительно ускоряет процесс по сравнению с глобальной сортировкой. Обычно используют стандартные алгоритмы сортировки (например, быструю сортировку или сортировку слиянием).
Объединение отсортированных блоков
Этот этап выполняется через слияние отсортированных блоков. В случае большого числа блоков используют методы многократного слияния, например, очередь слияния или кучу.
Финальное слияние и окончательная сортировка
После многократных этапов слияния получается уже почти отсортированный массив. В финале происходит окончательная фиксация порядка и подготовка данных к использованию.
Преимущества и недостатки блочной сортировки
Как любой алгоритм, блочная сортировка обладает своими сильными и слабыми сторонами. Важно знать их, чтобы правильно применять данный метод в своих проектах.
Преимущества
- Высокая скорость при больших объемах данных — благодаря параллельной обработке.
- Масштабируемость — легко расширяет системные ресурсы.
- Гибкость — адаптируется под разные типы данных.
- Низкая чувствительность к ошибкам — если один блок сортируется неправильно, он не влияет на весь массив.
Недостатки
- Сложность реализации — требует продуманной организации процессов разделения и слияния.
- Потребность в значительных системных ресурсах — особенно при большом числе блоков.
- Задержки при недостатке ресурсов — например, при нехватке памяти или каналов связи.
Для минимизации недостатков важно грамотно планировать архитектуру системы и выбирать оптимальные параметры разделения данных.
Практическое применение блочной сортировки в распределённых системах
Блочная сортировка широко применяется в различных областях, где необходимо обрабатывать огромные объемы информации. Рассмотрим наиболее распространённые сценарии:
Обработка больших баз данных
При работе с крупными базами данных, превышающими оперативную память, блочная сортировка позволяет разбивать данные на управляемые части, быстро сортировать и объединять их без перезагрузки системы.
Веб-сервисы и аналитика
При анализе пользовательских данных, логов или транзакций блочная сортировка помогает ускорить процессы поиска и выявления закономерностей путем параллельной обработки данных.
Облачные системы и распределённые вычисления
В облачных инфраструктурах блочная сортировка интегрируется с системами MapReduce и Hadoop, где каждый узел занимается сортировкой своего блока, что существенно ускоряет обработку массивных данных.
Преимущества использования:
| Преимущество | Описание |
|---|---|
| Масштабируемость | Легко расширять инфраструктуру по мере роста данных |
| Параллельная обработка | Многопоточность ускоряет выполнение задач |
| Эффективное использование ресурсов | Оптимальное распределение нагрузки |
Практический совет
При внедрении блочной сортировки в распределенных системах важно учитывать особенности сетевых задержек и безопасность данных. Не рекомендуем комбинировать блочную сортировку с менее надежными схемами передачи информации — результат может пострадать.
Блочная сортировка — это один из самых мощных инструментов при работе с массивами данных большого объема, особенно в распределенных системах. Ее преимущества — высокая скорость, масштабируемость и возможность параллельной обработки — делают её неотъемлемой частью современных решений, связанных с обработкой данных.
Однако не стоит забывать о сложности реализации и ресурсных требованиях. Важно заранее продумывать архитектуру системы, знать параметры разделения данных и уметь управлять процессами слияния.
Если вы планируете внедрять блочную сортировку в своих проектах, рекомендуем провести тестирование на типичных наборах данных, настроить параметры разделения и оптимизировать процессы слияния. Это поможет добиться максимальной эффективности и снизить возможные риски.
Понимание и правильное применение этого метода позволит значительно ускорить обработку больших объемов информации и сделать ваши системы более устойчивыми и масштабируемыми.
Вопрос-ответ
Вопрос: Почему при работе с большими данными блочная сортировка бывает предпочтительнее стандартных алгоритмов?
Ответ: Блочная сортировка позволяет разделить большой объем информации на управляемые части, что значительно ускоряет обработку за счет параллельной сортировки и слияния. Она особенно хорошо подходит для систем с ограниченными ресурсами или при работе с данными, превышающими объем оперативной памяти, так как ограничивает количество одновременно обрабатываемых данных. Стандартные алгоритмы, такие как быстрая сортировка или сортировка слиянием, в этом случае зачастую требуют слишком много времени или памяти, а блочная сортировка помогает оптимизировать использование ресурсов и снизить задержки в обработке.
Дополнительные материалы
Подробнее
| Первая ссылка | Вторая ссылка | Третья ссылка | Четвертая ссылка | Пятая ссылка |
| Объем больших данных и их обработка | Алгоритмы сортировки для распределённых систем | Параллелизация обработки данных | Эффективная работа с базами данных | Обработка логов в реальном времени |
| Использование Hadoop и MapReduce | Оптимизация ресурсов при больших данных | Параллельные алгоритмы сортировки | Объединение больших данных | Обработка потоковых данных |