Bucket Sort: Мощный инструмент для сортировки данных и его удивительные возможности
Когда мы сталкиваемся с необходимостью упорядочить большие объемы числовых данных, часто ищем самые эффективные алгоритмы сортировки․ Среди них особое место занимает Bucket Sort — метод, который не только обеспечивает высокую скорость работы, но и часто оказывается настолько простым в реализации, что сразу же становится любимым инструментом любого программиста․ В этой статье мы подробно разберем, что такое Bucket Sort, как он работает, в каких случаях лучше применять этот алгоритм и как правильно его реализовать, чтобы получать максимально быстрый и надежный результат․
Что такое Bucket Sort? Общее описание принципа
Bucket Sort, это алгоритм сортировки, основанный на разбиении исходного массива на несколько групп или «ведер» (buckets)․ После этого каждая группа сортируется отдельно, и в конце происходит объединение отсортированных данных․ Идея этого подхода заключается в распараллеливании процесса сортировки и уменьшении общей сложности выполнения за счет локальной сортировки небольших участков данных․
Основные особенности Bucket Sort:
- Распределение данных по ведрам — исходный массив разбивается на диапазоны значений, которые попадают в разные ведра․
- Локальная сортировка — внутри каждого ведра применяется более быстрый алгоритм, например, сортировка вставками или сортировка выбором․
- Объединение результатов — после сортировки внутри ведер, все ведра объединяются в один отсортированный массив․
Этот алгоритм особенно эффективен, когда данные равномерно распределены по диапазону, и есть возможность разбить их на ведра с одинаковым или близким диапазоном․
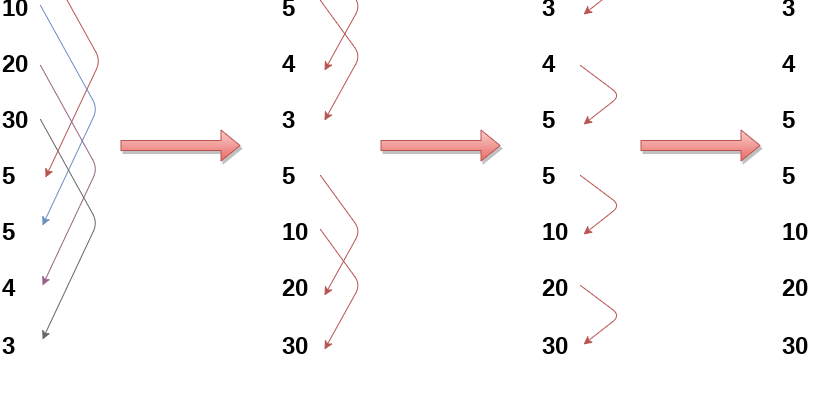
Как работает Bucket Sort? Процесс пошагово
Чтобы понять, как именно реализуется данный метод, разберем основные этапы его работы:
Шаг 1: Определение диапазона и количества ведер
На первом этапе необходимо определить минимальное и максимальное значение в исходных данных, а также выбрать количество ведер․ Обычно, чем больше ведер, тем выше потенциальная скорость сортировки, однако и нагрузка на процессор увеличивается․
Шаг 2: Распределение элементов по ведрам
Далее каждый элемент исходного массива размещается в соответствующее ведро по своему значению․ Для этого используют формулу, которая вычисляет индекс ведра для каждого элемента:
index = floor((element_value ⎼ min_value) / bucket_range)
где bucket_range — диапазон значений одного ведра․
Шаг 3: Локальная сортировка ведер
После распределения элементов по ведрам внутри каждого ведра применяется любой подходящий алгоритм сортировки — зачастую используют сортировку вставками, потому что внутри ведра данных обычно небольшой объём․
Шаг 4: Объединение всех ведер
Когда все ведра отсортированы, их просто объединяют в один конечный массив — он и оказывается отсортированным по возрастанию․
| Этап | Описание | Ключевые особенности |
|---|---|---|
| Определение диапазона | Нахождение min и max значения, выбор количества ведер | Зависит от распределения данных |
| Распределение элементов | Присвоение каждому элементу своего ведра по формуле | Равномерность важна для эффективности |
| Локальная сортировка | Сортировка внутри каждого ведра | Использование быстрого алгоритма внутри ведра |
| Объединение | Объединение всех отсортированных ведер | Обеспечивает итоговую сортировку массива |
Преимущества и ограничения Bucket Sort
Преимущества
- Высокая скорость при равномерном распределении данных, благодаря локальной сортировке ведер уменьшается время работы;
- Параллелизм — сортировка ведер может выполняться одновременно, что дополнительно повышает производительность․
- Простота реализации — алгоритм легко реализовать даже на начальном уровне․
Ограничения
- Неэффективность при неравномерном распределении данных — если данные сконцентрированы в одном ведре, выигрыша не будет․
- Зависимость от диапазона данных, выбор количества ведер и диапазона очень важен для эффективной работы․
- Дополнительная память — требуется место для хранения ведер․
Рассмотрим в таблице сравнительную характеристику Bucket Sort с классическими алгоритмами:
| Алгоритм | Сложность по времени | Память | Особенности |
|---|---|---|---|
| Bucket Sort | O(n + k), при равномерном распределении | Дополнительная | Распределение по ведрам, локальная сортировка |
| Quicksort | O(n log n), в худшем случае O(n^2) | Маленькая | Репликация, разделение |
| Merge Sort | O(n log n) | Большая | Объединение отсортированных массивов |
Реализация Bucket Sort на практике: советы и примеры
Теперь, когда мы понимаем теоретическую основу алгоритма, самое время рассмотреть, как реализовать его на практике․ Представим пример — сортировка массива случайных чисел в диапазоне от 0 до 1․ Ниже приведен пример кода на языке JavaScript, который демонстрирует основные этапы выполнения Bucket Sort:
function bucketSort(arr, bucketCount = 10) {
if (arr․length === 0) {
return arr;
}
const minValue = Math․min(․․․arr);
const maxValue = Math․max(․․․arr);
const bucketSize = (maxValue ⎼ minValue) / bucketCount;
const buckets = Array․from({ length: bucketCount }, => []);
// Распределение по ведрам
for (let i = 0; i < arr․length; i++) {
const index = Math․min(
Math․floor((arr[i] ౼ minValue) / bucketSize),
bucketCount ౼ 1
);
buckets[index]․push(arr[i]);
}
// Сортировка внутри ведер
for (let i = 0; i < buckets․length; i++) {
buckets[i]․sort((a, b) => a ⎼ b); // Можно использовать сортировку вставками
}
// Объединение
return []․concat(․․․buckets);
}
Эта реализация показывает, как легко можно применить Bucket Sort в реальных задачах․ Важно помнить, что выбор количества ведер, ключевой момент, требующий экспериментов в зависимости от ассортимента данных․
Вопрос: Можно ли использовать Bucket Sort для сортировки строк или других нечисловых данных?
Bucket Sort в основном предназначен для числовых данных, поскольку его механизм основан на распределении по диапазонам․ Для строк или других типов данных используют вариации алгоритма или другие подходы, такие как сортировка по ключам или использование специальных структур данных, например, деревьев или хеш-таблиц․ В случае строк, можно предварительно преобразовать их в числовой формат или использовать метод сабстрингов для определения диапазона․ Однако, наиболее эффективен он именно для чисел, особенно с равномерным распределением․
Подробнее
| библиотеки для Bucket Sort | примеры сортировки больших массивов | сравнение алгоритмов сортировки | эффективность Bucket Sort | оптимизация Bucket Sort |
| лучшие ситуации для Bucket Sort | разбор сложных задач сортировки | реализация на Python | учимся оптимизировать алгоритмы | примеры использования Bucket Sort |