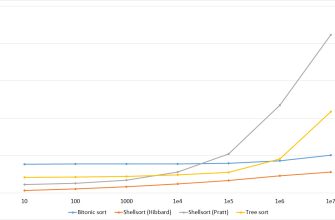
Bucket Sort: Полное руководство по эффективному распределению и сортировке данных
В современном мире обработки данных и алгоритмов сортировки поиск эффективных методов организации информации становится всё более актуальным. Среди множества алгоритмов, заслуживающих внимания, особенно выделяется Bucket Sort. Этот метод хорошо подходит для сортировки числовых данных, расположенных в ограниченном диапазоне, и позволяет существенно ускорить процесс при правильном использовании. В этой статье мы подробно разберем, как работает Bucket Sort, его преимущества и недостатки, а также особенные случаи применения.
Что такое Bucket Sort и зачем он нужен?
Bucket Sort – это алгоритм сортировки, основанный на идее разделения исходных данных на несколько подсписков (ведер), которые затем сортируются отдельно и объединяются. Изначально весь набор данных разбивается по диапазону — от минимального до максимального значений, и каждый элемент отправляется в определенное ведро на основе своего значения. После этого каждое ведро сортируется локально при помощи более простых методов, таких как вставка или сортировка пузырьком. В конце все ведра объединяются в один отсортированный массив.
Главная идея: разделить сложную задачу сортировки на несколько более мелких и простых операций, что увеличит скорость обработки больших объемов данных.
Преимущества Bucket Sort
- Высокая эффективность при равномерном распределении данных: если данные равномерно распределены по диапазону, алгоритм работает очень быстро.
- Параллельность: каждая корзина может сортироваться независимо и одновременно, что удобно для реализации на многопроцессорных системах.
- Легкая адаптация: алгоритм хорошо работает для числовых данных с ограниченным диапазоном значений.
Недостатки Bucket Sort
- Неэффективен при неравномерном распределении данных: если большинство элементов сконцентрированы в одном ведре, эффективность падает.
- Дополнительная память: требуется место для хранения всех корзин.
- Требует знания диапазона данных заранее: для правильного распределения элементов нужно знать минимальное и максимальное значение исходных данных.
Как работает Bucket Sort: шаг за шагом
Определение диапазона данных
Первый и очень важный этап – это определение минимального и максимального значения в наборе данных. От этого зависит правильность распределения элементов по корзинам. Например, если мы сортируем оценки студентов, диапазон может быть от 0 до 100. Для чисел, разброс которых значительно больше, рекомендуется разбивать диапазон на равные сегменты.
Создание корзин
На втором этапе создается набор ведер, каждое из которых предназначено для определенного диапазона значений. Обычно используется массив или список корзин, где каждая корзина — это отдельная структура, например, список или массив.
Практический пример: при диапазоне от 0 до 100, можно сделать 10 корзин:
| Корзина № | Диапазон значений | Область применения |
|---|---|---|
| 1 | 0, 9 | Маленькие оценки или маленькие числа |
| 2 | 10 — 19 | |
| 3 | 20 — 29 | |
| 4 | 30 — 39 | |
| 5 | 40 — 49 | |
| 6 | 50 — 59 | |
| 7 | 60 — 69 | |
| 8 | 70 — 79 | |
| 9 | 80 — 89 | |
| 10 | 90, 99 | Высокие оценки |
Распределение элементов по корзинам
Каждый элемент, исходя из своего значения, помещается в соответствующую корзину. Для этого необходимо вычислить индекс корзины по формуле:
Индекс корзины = floor((значение ― минимальное значение) / размер диапазона)
Например, число 73 при диапазоне 0-100 и 10 корзинах попадет в корзину с индексом 7, потому что:
- делим разность 73 и 0 на диапозон 10: (73 — 0)/10 = 7.3
- поэтому число идет в 8-ю корзину (индекс 7)
Локальная сортировка корзин
Каждая корзина сортируется самостоятельно. Обычно используют простые алгоритмы сортировки — insertion sort, bubble sort или quicksort, в зависимости от размера корзины.
Объединение корзин
После сортировки всех корзин, объединяем их содержимое — по очереди, начиная с первой до последней, получая итоговый отсортированный массив.
Практический пример реализации Bucket Sort на Python
Приведем пример реализации алгоритма на языке Python (в стиле псевдокода с включенными комментариями):
def bucket_sort(arr): min_value = min(arr) max_value = max(arr) bucket_count = 10 # Создаем пустые корзины buckets = [[] for _ in range(bucket_count)] # Распределение элементов по корзинам for num in arr: index = int((num ― min_value) / (max_value — min_value + 1) * bucket_count) buckets[index].append(num) # Сортировка каждой корзины for bucket in buckets: bucket.sort # Объединение отсортированных корзин sorted_array = [] for bucket in buckets: sorted_array.extend(bucket) return sorted_array
Данный пример хорош тем, что легко понимается и дает хорошее представление о процессе.
Ключевые моменты и советы по использованию Bucket Sort
- Знайте диапазон ваших данных: чтобы правильно разбивать значения, необходимо знать минимальные и максимальные значения.
- Равномерное распределение: алгоритм работает лучше при равномерном распределении данных.
- Настройка числа корзин: увеличение количества корзин повышает точность, но увеличивает и потребление ресурсов.
- Выбор сортировки внутри корзин: для небольших корзин используйте простую сортировку, а для больших — более эффективную.
- Используйте параллельную обработку: параллельное сортирование корзин увеличит скорость при наличии многопроцессорных систем.
Когда использовать Bucket Sort?
Этот алгоритм отлично подойдет в случаях, когда:
- Данные равномерно распределены по диапазону.
- Объем данных очень большой, и требуется высокая скорость обработки.
- Нужно сортировать числовые данные в ограниченном диапазоне.
- Реализация должна быть параллельной или распараллеленной.
Несмотря на свои преимущества, для данных с сильной концентрацией или очень широким диапазоном лучше использовать другие алгоритмы типа Quicksort или Mergesort.
Общие рекомендации и выводы
Bucket Sort — это мощный и гибкий инструмент при правильной постановке задачи. Он отлично подходит для обработки большого объема числовых данных, особенно если они равномерно распределены по диапазону. Однако важно учитывать ограничения и специфику данных, чтобы выбрать наиболее эффективный алгоритм. Разрабатывая собственные реализации, стоит учитывать работу с памятью, а также возможности многопоточности.
Вопрос: Можно ли использовать Bucket Sort для сортировки строк или сложных объектов?
Ответ: Bucket Sort преимущественно применим для числовых данных, так как распределение элементов по корзинам основано на их числовых диапазонах. Для строк или сложных объектов обычно используют Лексикографическую сортировку или специальные алгоритмы, такие как Radix Sort или Counting Sort. Однако, если можно преобразовать объекты в числовое значение или ключ, например, через хэширование или получение числового признака, то Bucket Sort можно адаптировать и под такие задачи, но это требует дополнительной осторожности и учета особенностей данных.
Подробнее
| эффективность Bucket Sort | применение Bucket Sort | лучшие случаи Bucket Sort | сравнение Bucket Sort и Radix Sort | минусы Bucket Sort |
| пример реализации Bucket Sort | правильная организация корзин | оптимизация Bucket Sort | самые быстрые сортировки | проблемы при нерегулярных данных |
| алгоритм Bucket Sort | когда использовать Bucket Sort | разделение данных в Bucket Sort | лучшие практики | сложности Bucket Sort |
| параллельное выполнение Bucket Sort | структура данных для Bucket Sort | интересные особенности Bucket Sort | сложность реализации | лучшие параметры для Bucket Sort |
| сравнение Bucket Sort и Counting Sort | плюсы и минусы Bucket Sort | методы оптимизации Bucket Sort | особенности реализации на C++ | обзор лучших методов сортировки |