Bucket Sort: Тайны эффективной сортировки и распределения данных
Когда речь заходит о обработке и сортировке больших объемов данных‚ каждый программист сталкивается с вопросом: какой алгоритм выбрать для достижения максимальной эффективности? Среди множества существующих методов особое место занимает алгоритм Bucket Sort‚ или сортировка с использованием корзин. Этот подход известен своей способностью эффективно работать при определенных условиях‚ обеспечивая быструю сортировку и минимальные вычислительные затраты. В этой статье мы подробно расскажем о сути алгоритма‚ принципах его работы‚ областях применения и тонкостях реализации.
Что такое Bucket Sort и как он работает?
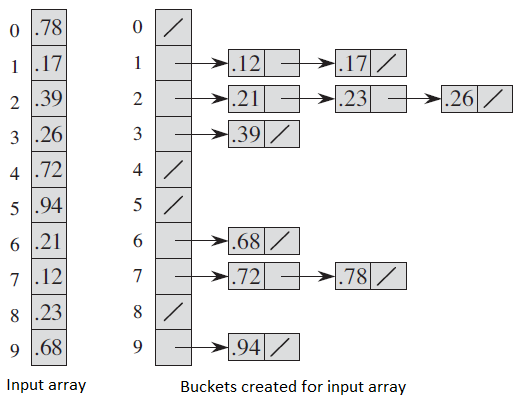
Bucket Sort — это метод сортировки‚ основанный на идее распределения элементов по «корзинам» (buckets)‚ каждая из которых позже сортируется индивидуально. Этот алгоритм особенно эффективен для сортировки числовых данных‚ распределенных равномерно в некотором диапазоне‚ что позволяет значительно сократить время выполнения сортировки по сравнению с классическими алгоритмами.
Общая схема работы Bucket Sort выглядит следующим образом:
- Определение диапазона значений и количества корзин.
- Распределение элементов по корзинам в соответствии с их значениями.
- Сортировка элементов внутри каждой корзины (чаще всего — при помощи другого алгоритма).
- Объединение отсортированных корзин в один отсортированный массив.
Приведем схематическое изображение процесса:

Основные этапы работы алгоритма
Выбор диапазона и количества корзин
Прежде чем приступить к распределению данных‚ необходимо определить диапазон значений — минимальное и максимальное значение в исходных данных. На его основе вычисляется количество корзин. Обычно число корзин выбирают равным примерно количеству элементов‚ либо использует формулу‚ основанную на диаметре диапазона и предполагаемой плотности распределения данных.
Распределение элементов по корзинам
Значения элементов определяются с помощью формулы:
bucket_index = floor( (value ‒ min_value) / (max_value ‒ min_value) * number_of_buckets )
Эта формула гарантирует‚ что элементы попадут в соответствующие корзины в зависимости от их значения. Важно правильно выбрать количество корзин‚ чтобы избежать слишком сильной перегрузки одной корзины или их недостаточного разделения.
Сортировка внутри корзин
После распределения все элементы внутри каждой корзины сортируются при помощи выбранного алгоритма. Обычно используют вставочную сортировку для небольших корзин или бинарный поиск при работе с более крупными наборами данных. Для эффективности хорошо подходит комбинация: корзины сортируются простым методом‚ а в целом — распараллеливание обработки корзин.
Объединение результатов
После сортировки внутри всех корзин происходит объединение всех отсортированных элементов в один итоговый массив. Порядок корзин остается неизменным‚ что обеспечивает сохранение сортировки и итоговую правильность.
Плюсы и минусы алгоритма Bucket Sort
| Плюсы | Минусы |
|---|---|
|
|
Когда применять Bucket Sort?
Идеальное применение алгоритма — это ситуации‚ когда:
- Данные равномерно распределены в некотором диапазоне.
- Объем данных очень большой‚ и важна скорость выполнения.
- Есть возможность параллелизировать обработку корзин.
- Необходима высокая точность и предсказуемость времени сортировки.
Если данные имеют сильные отклонения или неравномерную плотность распределения‚ лучше рассмотреть другие алгоритмы‚ например‚ QuickSort или MergeSort;
Практическая реализация алгоритма на языке Python
Для наглядности покажем пример кода‚ реализующего Bucket Sort:
def bucket_sort(array‚ num_buckets=10):
if len(array) == 0:
return array
min_value = min(array)
max_value = max(array)
# Создаем корзины
buckets = [[] for _ in range(num_buckets)]
# Распределяем элементы по корзинам
for value in array:
index = int((value ౼ min_value) / (max_value ‒ min_value + 1e-9) * num_buckets)
buckets[index].append(value)
# Сортируем каждую корзину и объединяем
sorted_array = []
for bucket in buckets:
sorted_array.extend(sorted(bucket))
return sorted_array
Пример использования
data = [0.42‚ 0.32‚ 0.23‚ 0.52‚ 0.25‚ 0.47‚ 0.55‚ 0.31‚ 0.41]
print(bucket_sort(data))
Особенности реализации и советы по оптимизации
При использовании Bucket Sort необходимо учитывать несколько аспектов для оптимальной работы:
- Выбор числа корзин влияет на скорость и качество сортировки—лучше его подбирать‚ исходя из объемов данных и плотности распределения.
- Для сортировки внутри корзин можно использовать более быстрые или подходящие для небольших объемов алгоритмы.
- Обработка больших данных с помощью параллелизации существенно ускоряет работу.
Алгоритм Bucket Sort по праву заслужил свою репутацию как быстрый и гибкий инструмент для сортировки равномерных и больших коллекций данных при правильном выборе параметров. Его преимущества — параллелизация‚ эффективность и возможность комбинировать с другими алгоритмами — делают его ценным инструментом в арсенале программиста.
Однако важно помнить‚ что успех зависит от правильного выбора диапазона и числа корзин‚ а также от типа данных. В случаях‚ когда распределение данных неравномерно или их больше‚ стоит рассматривать альтернативные методы.
Обратите внимание:
Это один из многих алгоритмов сортировки‚ и правильный выбор зависит от конкретных условий задачи. Не бойтесь экспериментировать и тестировать разные подходы!
Вопрос к статье
Как понять‚ подходит ли алгоритм Bucket Sort для обработки конкретных данных и что делать‚ если распределение данных неравномерное?
Если ваши данные равномерно распределены в заданном диапазоне‚ и объем данных очень большой‚ Bucket Sort станет отличным выбором благодаря своей скорости и возможности параллельной обработки. В случае неравномерного распределения‚ эффективность значительно снижается‚ поскольку корзины могут стать либо слишком перегруженными‚ либо малозагруженными. В таких ситуациях рекомендуется предварительно анализировать распределение данных и‚ при необходимости‚ использовать альтернативные алгоритмы сортировки‚ например‚ QuickSort или MergeSort‚ которые менее чувствительны к плотности распределения элементов.
Подробнее
| эффективность bucket sort | виды распределения данных | преимущества bucket sort | недостатки сортировки корзинами | пример реализации на Python |
| эффективен при равномерных данных | тяжелое неравномерное распределение | параллельная обработка‚ высокая скорость | зависимость от правильного выбора параметров | доступен пример на Python |