Как эффективно искать медиану с помощью сортировки: разбор методов и практических подходов
При работе с большими наборами данных одной из ключевых задач аналитика становится определение центральной тенденции — медианы. Медиана — это значение, которое делит упорядоченные данные на две равные части. Однако, как найти её быстро и эффективно, особенно при большом объеме данных? В этом материале мы разберем методы сортировки и алгоритмы поиска медианы, поделимся практическими советами и покажем, какие подходы наиболее подходят для различных сценариев.
Почему важно знать методы поиска медианы?
Медиана — это одна из наиболее устойчивых статистических мер, поскольку она недостаточно чувствительна к экстремальным значениям, в отличие от среднего арифметического. Именно поэтому в большинстве аналитических задач, связанных с неравномерным распределением данных или наличием выбросов, медиана становится предпочтительным показателем.
Нередко бывает так, что для определения среднего значения на больших датасетах используют сортировку, однако это может быть затратным в вычислительном плане. Именно поэтому существуют более эффективные алгоритмы поиска медианы без полного упорядочивания всего массива. Понимание этих методов важно для оптимизации процессов и экономии ресурсов.
Классическая сортировка для поиска медианы
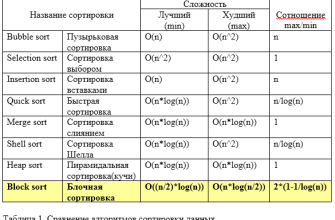
Самый интуитивный и понятный способ — отсортировать весь массив и выбрать центральное значение или значение двух центров, если размер массива четный. Данный метод хорош для небольших данных и учебных целей, однако при больших объемах становится очень медленным.
Пошаговая процедура:
- Выполнить сортировку данных (например, сортировка слиянием, быстрой сортировкой или сортировкой пузырьком).
- Определить размер массива N.
- Если N нечетное, выбрать элемент с индексом (N+1)/2 (по умолчанию нумерация с 1).
- Если N четное — взять средние два элемента и вычислить их среднее арифметическое.
Этот подход, хотя и прост, отнимает много времени при больших объемах данных — временная сложность обычно составляет O(N log N). Так что, если нам нужна только медиана, есть смысл искать более быстрые методы.
Алгоритм поиска медианы без полной сортировки
Одним из наиболее эффективных методов является алгоритм выборки по типу "quickselect". Он основан на идее быстрой сортировки (quicksort), но фокусируется только на поиске k-го по порядку элемента, а не на полном упорядочивании массива.
Что такое алгоритм quickselect?
Это алгоритм, который использует принцип разделения массива на части и рекурсивно ищет нужное значение.
Проще говоря, он делает следующее:
- Выбирает опорный элемент (могут быть разные стратегии выбора).
- Разделяет массив так, чтобы все элементы меньше опорного оказались слева, а все больше — справа.
- Проверяет позицию элемента относительно целевой — k-го по порядку.
- Если позиция совпадает — возвращает найденное значение.
- Если позиция больше, ищет в левой части, если меньше, в правой.
Плюсы и минусы quickselect
| Плюсы | Минусы |
|---|---|
| Средняя сложность O(N) | Масса худших случаев (O(N^2)), если не выбран опорный элемент удачно |
| Поиск медианы — очень быстрый способ для больших данных | Немного сложнее в реализации, чем простая сортировка |
Важно учитывать, что алгоритм подойдет для быстрого определения медианы в динамических данных или при необходимости многократных расчетов.
Метод "медиана из двух отсортированных массивов"
Еще один подход — это использование свойства, что медиана двух отсортированных массивов со средним размером, это более узкая задача, нежели сортировка всего массива. Этот метод доказал свою эффективность в задачах, связанных с объединением данных.
Где применяется этот метод?
- Обработка данных из двух источников, где каждый источник отсортирован.
- Медицинские исследования, финансовый анализ — ситуации, когда нужно объединить два отсортированных набора и найти медиану.
Основная идея — осуществить «слияние» двух массивов до тех пор, пока не будет достигнута медиана, без полной сортировки всего массива.
Практический пример, поиск медианы в списке случайных чисел
Рассмотрим практическую задачу: у нас есть массив из 100000 случайных чисел, и нам нужно быстро найти его медиану. Используем классический подход — сортировали бы весь массив, что занимает много времени. Вместо этого применим алгоритм quickselect.
Пошаговые действия:
- Создаете массив из 100000 элементов случайных чисел.
- Определяете, нужен ли вам один элемент (при нечетном размере) или среднее двух (при четном).
- Запускаете алгоритм quickselect на поиск соответствующего элемента.
- Получаете результат — медиана за значительно меньшие ресурсы.
Для реализации этого подхода используют популярные языки программирования — Python, Java, C++. В статье ниже представим пример кода на Python для quickselect.
Пример реализации на Python:
def quickselect(arr, k):
if len(arr) == 1:
return arr[0]
pivot = arr[len(arr) // 2]
lows = [el for el in arr if el < pivot]
highs = [el for el in arr if el > pivot]
pivots = [el for el in arr if el == pivot]
if k < len(lows):
return quickselect(lows, k)
elif k < len(lows) + len(pivots):
return pivot
else:
return quickselect(highs, k ౼ len(lows) ⸺ len(pivots))
import random
array = [random.randint(1, 1000000) for _ in range(100000)]
n = len(array)
if n % 2 == 1:
median = quickselect(array, n // 2)
else:
median = (quickselect(array, n // 2 ⸺ 1) + quickselect(array, n // 2)) / 2
print(f"Медиана массива: {median}")
Данный код значительно быстрее, чем полная сортировка, особенно на больших объемах данных.
Обзор, какой метод выбрать?
Для практического использования важно понять, что подход зависит от ситуации:
- Полная сортировка — подходит для небольшой выборки или учебных целей.
- Quickselect — самый быстрый и эффективный для больших наборов данных.
- Медиана двух отсортированных массивов — применима, если у вас есть два подготовленных отсортированных массива.
- Онлайн-алгоритмы, для динамических данных, когда новые значения добавляются постоянно.
Выбор методов зависит от объема данных, наличия предварительной сортировки и требований к скорости вычислений.
Обнаружение медианы — важная задача, которая часто возникает при анализе данных. Основное правило — для небольших наборов подойдет сортировка и выбор центрального элемента. Для больших и динамических данных лучше использовать алгоритмы выбора k-го элемента, такие как quickselect.
С практической точки зрения, освоение алгоритмов и понимание их сложности позволяют значительно упростить и ускорить аналитические процессы. Овладение этими инструментами — это ключ к более эффективной работе с данными в различных сферах: от финансовой аналитики до медицины и машинного обучения.
Вопрос: Почему использование алгоритма quickselect быстрее для поиска медианы, чем полный сортированный массив?
Ответ: Потому что алгоритм quickselect нацелен только на поиск нужного элемента (медианы) и не требует полного упорядочивания всего массива, что снижает временную сложность до среднего O(N). В то время как полный сортировочный алгоритм сортирует весь массив, тратя больше ресурсов и времени, даже если нам важен только один элемент, медиана. Таким образом, quickselect оптимален для поиска медианы в больших данных благодаря своей эффективности и меньшему затрату вычислений.
Подробнее
| Метод quickselect для поиска медианы | Сортировка для поиска медианы | Алгоритм выбора k-го элемента | Объединение двух отсортированных массивов | Примеры кода на Python |
| Сложность алгоритмов поиска медианы | Эффективность методов | Применение на практике | Особенности работы с большими данными | Советы экспертов по выбору метода |