Как эффективно сортировать строки с помощью Counting Sort: подробное руководство
Когда речь заходит о сортировке данных, большинство из нас сразу вспоминает классические алгоритмы, такие как быстрая сортировка или сортировка слиянием․ Однако есть алгоритмы, которые идеально подходят для определённых задач и позволяют достигать высокой эффективности․ Одним из таких является Counting Sort․ В этой статье мы подробно разберём, как применить алгоритм Counting Sort для сортировки строк, о его преимуществах, особенностях реализации и практических примерах․ Мы поделимся собственным опытом и расскажем, почему этот метод может стать вашим незаменимым инструментом при работе с определёнными типами данных․
Что такое Counting Sort и почему он эффективен?
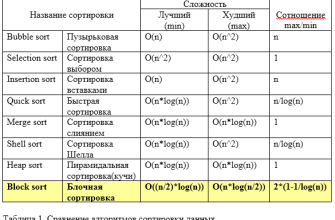
Counting Sort — это неинтуитивный, но очень быстрый алгоритм сортировки, который основан на подсчёте количества элементов․ В отличие от сравнивающих алгоритмов, он использует информацию о диапазоне данных, что позволяет ему достигать временной сложности O(n + k), где n — число элементов, а k — диапазон возможных значений․ Он особенно хорошо работает с целыми числами небольшого диапазона, но при правильной адаптации его можно использовать и для строк․
В случае с сортировкой строк Counting Sort становится сложнее, поскольку строки состоят из последовательности символов, и диапазон возможных символов может быть больше, чем в случае с целыми числами․ Однако, при использовании подхода поэлементного сравнения и разбивания по символам, алгоритм показывает хорошие результаты, особенно когда строки имеют одинаковую длину или если мы сортируем по определённым позициям символов․
Основные принципы работы Counting Sort для строк
Для того чтобы понять, как применить Counting Sort к строкам, необходимо ознакомиться с его фундаментальной концепцией․ В процессе сортировки строк, мы можем использовать следующий подход:
- Рассматриваем строки как последовательности символов․
- Определяем порядок сортировки — по какому именно признаку мы сортируем: по первому символу, по последнему, по всему слову или по определённой его части․
- Применяем подсчёт количества строк для каждого уникального символа выбранной позиции․
- На основе полученных данных формируем отсортированный массив․
Этот процесс позволяет эффективно сгруппировать строки по признаку и отсортировать их, не сравнивая каждую строку с другой, а используя таблицу подсчёта․ Такой метод особенно актуален, если в данных преобладает большой объём одинаковых элементов или если строки имеют одинаковую длину;
Практическая реализация Counting Sort для строк
Рассмотрим пример реализации алгоритма на языке программирования Python․ Представим, что нам даны строки одинаковой длины, и нам нужно их отсортировать по символам с позиции k․ Вот пример:
def counting_sort_strings(arr, index):
# Предполагается, что все строки имеют одинаковую длину
# и index — позиция символа по которой осуществляется сортировка
# Алфавит — все символы ASCII
alphabet_size = 256
count = [0] * alphabet_size
output = ["" for _ in range(len(arr))]
# Подсчёт количества строк по символу в позиции index
for s in arr:
ch = ord(s[index])
count[ch] += 1
# Обновляем массив подсчёта для получения индексов
for i in range(1, alphabet_size):
count[i] += count[i ‒ 1]
# Строим отсортированный массив
for s in reversed(arr):
ch = ord(s[index])
count[ch] -= 1
output[count[ch]] = s
return output
Пример использования
strings = ["cab", "abc", "bca", "bac", "acb"]
sorted_by_first_char = counting_sort_strings(strings, 0)
print(sorted_by_first_char)
Данный пример сортирует список строк по первому символу․ Аналогично можно применять сортировку по другим позициям, выполняя многократное прохождение по данным — так работает сортировка лексикографическим порядком (шейкер-сортировка)
Расширение метода: сортировка строк разной длины
Что делать, если строки имеют разную длину? В таких случаях приходится учитывать дополнительные нюансы․ Один из распространённых подходов — дополнить более короткие строки специальными символами, которые меньше любого другого символа, например, символом нулевого или пробела, чтобы все строки становились одинаковой длины․
Еще один способ, применять алгоритм, сортируя по последним символам и двигаясь к первому (обратный порядок)․ Такой метод называется растрированная сортировка (radix sort), и он часто используют в связке с Counting Sort для сортировки строк по позициям символов․
Практика и сложности реализации
Несмотря на то, что Counting Sort для строк кажется сложнее по сравнению с числовыми данными, его преимущества очевидны в определённых сценариях․ Он способен значительно сократить время обработки, если предварительно правильно подготовить данные․ Однако стоит помнить и о возможных сложностях:
- Больше памяти: при использовании таблицы подсчета для больших диапазонов символов․
- Поддержка разных языков: необходимость корректировать диапазон символов в зависимости от кодировки․
- Длина строк: необходимость дополнительной обработки при разной длине строк․
Важно также учитывать, что такой алгоритм отлично работает на наборах данных со статическими характеристиками и ограниченными диапазонами признаков․
Плюсы и минусы Counting Sort для строк
| Преимущества | Недостатки |
|---|---|
|
|
Вопрос: Почему Counting Sort может быть предпочтительным при сортировке строк в определённых случаях?
Ответ: Counting Sort может быть предпочтительным, потому что он обеспечивает очень быструю сортировку за счёт подсчёта количества элементов для каждого признака, что сокращает количество сравнений и уменьшает время обработки при ограниченном диапазоне символов и равной длине строк․ Этот алгоритм особенно эффективен при работе с большими объёмами данных, где присутствует много повторяющихся элементов или одинаковых префиксов․
Подробнее
| Что такое Counting Sort | Применение Counting Sort к строкам | Обработка строк разной длины | Преимущества Counting Sort для строк | Недостатки и ограничения |
| Что такое Counting Sort | Применение Counting Sort к строкам | Обработка строк разной длины | Преимущества Counting Sort для строк | Недостатки и ограничения |