Как эффективно сортировать строки с помощью Counting Sort: полное руководство
При работе с большими объемами данных часто возникает необходимость в быстрой и эффективной сортировке. Особенно это важно при обработке строк, когда стандартные алгоритмы могут уступать по скорости или требуют дополнительных ресурсов. В этой статье мы расскажем о том, как реализовать Counting Sort для строк, поделимся секретами оптимизации и расскажем, в каких случаях этот метод особенно полезен.
Что такое Counting Sort и почему его стоит использовать для строк
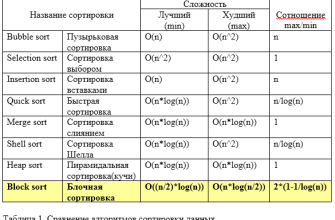
Counting Sort, это один из нестрассированных алгоритмов сортировки, который работает за линейное время при условии ограниченного диапазона элементов. В классической реализации он применяется для чисел в ограниченном диапазоне, однако при правильной адаптации его можно успешно использовать для строк. Преимущество этого метода — его высокая скорость и меньшие требования к памяти при определенных условиях.
Основная идея Counting Sort заключается в создании массива счетчиков для каждого возможного значения, затем, в накоплении их и, наконец, — в расстановке элементов на правильные позиции. Для строк, в частности, это означает, что мы можем использовать кодировку символов, например ASCII или Unicode, чтобы разбивать строки по символам и сортировать по каждому символу с помощью этого алгоритма.
Особенности реализации Counting Sort для строк
Обработка символов и кодировка
Перед тем как реализовать Counting Sort для строк, необходимо определить диапазон символов, который используется в данных. В большинстве случаев — это ASCII (от 0 до 127), либо расширенный Unicode, что увеличивает диапазон и потребует более объема памяти. Мы будем исходить из предположения, что строки состоят только из ASCII символов.
Если вы работаете с Unicode, важно подобрать подходящий диапазон символов или использовать более эффективные методы обработки. В большинстве практических случаев просто ограничение диапазона ASCII значительно упрощает работу и позволяет повысить скорость сортировки.
Модель алгоритма
- Шаг 1: Определяем длину строк и максимально возможную длину для корректной работы алгоритма.
- Шаг 2: Для каждой позиции символа, начиная с конца строки (или начала, в зависимости от алгоритма), выполняем сортировку методом Counting Sort по одному символу.
- Шаг 3: Собираем отсортированные строки, начиная с последней итерации.
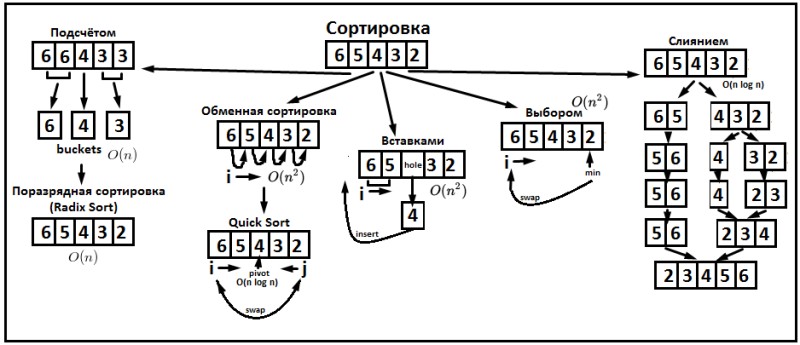
Данный подход — это своего рода реализация поразрядной сортировки, которая применяется к позициям символов в строках, начиная с конца (это называется «LSD» — Least Significant Digit).
Пошаговая реализация алгоритма
Код на Python для сортировки массива строк
def counting_sort_for_char(arr, index):
# Объявляем массив счетчиков, размером 256 для ASCII
count = [0] * 256
output = ["" for _ in range(len(arr))]
# Подсчет количества встреч каждого символа в данной позиции
for s in arr:
# Если длина строки меньше текущего индекса, используем 0 (например, добавляем символ для длинных строк)
if index < len(s):
char_code = ord(s[index])
else:
# Для коротких строк считаем символ как нулевой
char_code = 0
count[char_code] += 1
# Построение префиксных сумм
for i in range(1, 256):
count[i] += count[i ー 1]
# Распределение строк по результату
for s in reversed(arr):
if index < len(s):
char_code = ord(s[index])
else:
char_code = 0
count[char_code] -= 1
output[count[char_code]] = s
return output
def radix_sort_strings(arr):
if not arr:
return arr
max_len = max(len(s) for s in arr)
for i in range(max_len ー 1, -1, -1):
arr = counting_sort_for_char(arr, i)
return arr
Пример использования
strings = ["banana", "apple", "orange", "grape", "kiwi", "blueberry"]
sorted_strings = radix_sort_strings(strings)
print(sorted_strings)
Данный пример показывает, как с помощью итерации по символам, начиная с последних, можно отсортировать строки по всем позициям, используя Counting Sort на каждом шаге.
Преимущества и ограничения метода
Плюсы
- Высокая скорость: алгоритм работает за линейное время при ограниченном диапазоне символов.
- Низкое использование памяти: при использовании ASCII это особенно удобно, поскольку диапазон символов небольшой.
- Подходит для сортировки больших объемов данных: особенно когда все строки одинаковой длины или длины не очень большие.
Минусы
- Ограниченность диапазона символов: при работе с Unicode потребуется гораздо больше памяти или иной подход.
- Только для строк одинаковой или малоразличающейся длины: длинные строки увеличивают время выполнения.
- Неэффективность для случайных или очень разнообразных данных: при широком диапазоне символов преимущества теряются.
Практические советы по использованию Counting Sort для строк
- Определяйте диапазон символов: если работаете только с латиницей, лучше выбрать (ASCII). Для расширенных вариантов, подбирайте соответствующий диапазон.
- Обрабатывайте строки одинаковой длины: это ускорит алгоритм и сделает его более устойчивым к ошибкам.
- Используйте стабилизацию сортировки: сортировки по символам с конца позволяют получить полностью отсортированный массив в конце.
Дополнительные возможности
- Обработка специальных символов: можно дополнительно кодировать пробелы, знаки препинания и другие специальные символы.
- Интеграция с другими алгоритмами: Counting Sort отлично сочетается с QuickSort или MergeSort для предварительной обработки.
- Оптимизация памяти: при необходимости использовать биты или компрессию для хранения счетчиков в рамках узкого диапазона.
Обобщения и расширения алгоритма
Counting Sort можно расширить для сортировки строк, сочетающей в себе несколько критериев о порядке — например, по длине и по алфавиту. Также есть возможность использовать его как компонент более сложных систем сортировки и поиска, например, при реализации Radix Sort для строк.
Для Unicode-символов рекомендуется использовать вариации Radix Sort с учетом диапазона символов, а также подключать алгоритмы, использующие хэширование или деревья для обработки уникальных кодов символов.
Если вы работаете с большими массивами строк, связаны с ограниченным диапазоном символов и нуждаетесь в высокой скорости обработки — этот алгоритм станет отличным решением. Однако, при работе с множеством уникальных символов или длинных строк лучше рассмотреть другие подходы.
Главное — понять специфику ваших данных и выбрать наиболее подход який алгоритм. Counting Sort, мощный инструмент в арсенале разработчика, особенно для задач, где важна скорость и предсказуемость.
Вопрос: Можно ли применить Counting Sort для сортировки очень длинных строк или строк с разнообразным набором символов?
Ответ: Да, теоретически, можно, но на практике выполнение counting sort для длинных строк или данных с большим диапазоном символов становится неэффективным из-за высокой памяти и времени, которые потребуются. В таких случаях лучше использовать другие методы сортировки, например, Radix Sort с более оптимизированным управлением диапазона, или стандартные алгоритмы типа QuickSort или MergeSort, особенно если важна стабильность и универсальность.
Подробнее
| Поиск по строкам | Эффективные алгоритмы сортировки строк | Radix Sort для строк | Лучшие алгоритмы сортировки текстов | Оптимизация памяти при сортировке строк |
| Counting Sort для текста | Сортировка строк по алгоритму Counting Sort | Реализация Radix Sort для строк | Сравнение методов сортировки текста | Механизмы уменьшения памяти для сортировки |