Как правильно выполнить сортировку для медианы: пошаговая инструкция и лучшие практики
В мире обработки данных и анализа информации одна из ключевых задач — нахождение медианы в наборе чисел. Медиана, как известно, делит упорядоченный массив данных на две равные части и показывает центральное значение. Этот показатель особенно важен при работе с наборами данных с выбросами или асимметричным распределением, когда среднее арифметическое может искажать реальную картину.
При вычислении медианы зачастую приходится сначала отсортировать данные. Однако не всякая сортировка подходит для поиска медианы с точки зрения эффективности и скорости. В этом материале мы подробно рассмотрим различные подходы к сортировке для медианных вычислений и разберем, как добиться наилучших результатов в реальных задачах.
Что такое сортировка для медианы?
Сортировка для медианы — это процесс организации числового набора так, чтобы быстро определить его центральное значение. В зависимости от объема данных и требований к скорости, существует несколько методов выполнения данной задачи. В большинстве случаев нужно либо полностью отсортировать массив, либо использовать специальные алгоритмы, позволяющие найти медиану без полной сортировки.
Основные подходы:
- Полная сортировка массива: полностью отсортировать все элементы, а затем выбрать срединное.
- Использование алгоритмов поиска медианы: например, алгоритм «быстрой выборки» (Quickselect), который позволяет найти медиану за среднее линейное время, не сортируя весь массив.
Почему важно правильно выбрать сортировку для медианы?
Некорректная или неэффективная сортировка может привести к замедлению обработки данных, особенно при работе с большими наборами, где время выполнения критично. Если мы просто сортируем массив полностью, алгоритм может работать за сложность O(n log n), что допустимо для небольших объемов, но неэффективно для массивов миллионов элементов.
Использование специализированных алгоритмов, таких как Quickselect, позволяет значительно сократить время — до среднего O(n), что существенно экономит ресурсы и ускоряет вычисления. Поэтому понимание и правильное применение сортировки для медианы — залог быстрого и точного анализа.
Основные методы сортировки для поиска медианы
Полная сортировка массива
Самый очевидный способ — полностью отсортировать все данные и выбрать средний элемент.
Преимущества:
- Простота реализации.
- Подходит для небольших наборов данных.
Недостатки:
- Высокая сложность — O(n log n).
- Неэффективна при больших объемах.
Алгоритм Quickselect
Это алгоритм, основанный на методе быстрой сортировки, который позволяет искать k-й по порядку элемент (в нашем случае, медиану). Он не сортирует полностью весь массив, а лишь разделяет его части, работая только с той, которая содержит искомый элемент.
Преимущества:
- Средняя сложность, O(n).
- Высокая эффективность для больших данных.
Недостатки:
- В худшем случае сложность увеличивается до O(n^2).
- Может быть сложнее для реализации.
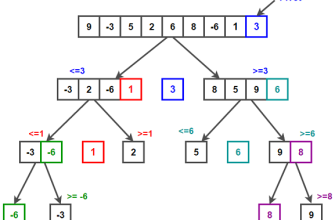
Пошаговая реализация метода быстрого выбора для поиска медианы
Рассмотрим, как на практике выполнить сортировку для медианы с помощью алгоритма Quickselect.
Шаг 1: Определение, что нужно найти
Для поиска медианы в массиве из нечетного количества элементов — средний элемент. Для четного — среднее из двух средних элементов.
Шаг 2: Выбор опорного элемента
На каждом этапе алгоритма выбирается случайный или фиксированный опорный элемент.
| Параметр | Описание |
|---|---|
| Опорный элемент | Элемент, вокруг которого происходит разделение массива. |
| Левый и правый указатели | Индексы элементов, между которыми ищется правильное место для опорного. |
Шаг 3: Разделение массива
Дисподиция элементов так, чтобы все меньше опорного оказались слева, большие — справа. После этого проверяется позиция опорного элемента относительно средней.
Шаг 4: Итеративное сужение
Если нужный индекс менее текущего, ищем в левой части, иначе — в правой. Процесс повторяется до нахождения нужного элемента.
Когда выбранный элемент занимает позицию медианы, алгоритм завершает работу, и мы получаем искомое значение.
Практический пример: поиск медианы с помощью Quickselect
Рассмотрим конкретный массив чисел:
некорректные данные: [12, 3, 5, 7, 19, 0, 15]
Задача — найти медиану этого набора.
Пошагово:
- Определяем, что массив содержит 7 элементов. Медитана — это 4-й элемент по порядку (индекс 3).
- Начинаем алгоритм, выбираем случайный опорный элемент, например, 5.
- Разделяем массив по этому элементу: слева — меньшие или равные 5, справа — большие.
- Определяем позицию опорного элемента. Если она совпадает с индексом медианы, останавливаемся.
- Если нет, повторяем процедуру для соответствующей части.
В результате после нескольких итераций мы быстро находим медианный элемент — например, 7 или 5 в зависимости от выбранного опорного.
Практические советы по использованию сортировки для медианы
Общая рекомендация — всегда учитывать объем данных и требования к скорости. При небольших наборах можно использовать полную сортировку, например, метод sort в стандартной библиотеке. Для больших данных предпочтительнее применять Quickselect или другие алгоритмы на основе разделения.
Также важно помнить о:
- Обработке выбросов — медиана устойчива к выбросам, поэтому при анализе данных с аномалиями лучше использовать именно ее.
- Оптимизации местной сортировки — например, применять алгоритм introsort или Timsort, встроенные в многие языки.
- Делегировании поиска медианы — использовать сторонние библиотеки или реализовать собственный алгоритм для максимально эффективной работы.
Выбор подходящего метода зависит от конкретных условий: объема данных, требований к скорости и доступных ресурсов. В большинстве случаев для небольших наборов данных подойдет простая полная сортировка. Однако при работе с большими массивами лучше использовать алгоритм Quickselect или его аналоги, чтобы значительно ускорить процесс.
Это особенно важно в приложениях, где обработка данных должна быть максимально быстрой — например, в системах аналитики, машинах обучения или при обработке потоковых данных. Освоив эти методы, мы можем значительно повысить эффективность своих инструментов анализа и сделать работу с данными более удобной и производительной.
Вопрос-ответ
Вопрос: Какие алгоритмы лучше всего подходят для поиска медианы в больших данных и почему?
Подробнее: 10 LSI-запросов по теме сортировки для медианы
Подробнее
| методы поиска медианы | быстрая сортировка для медианы | алгоритм quickselect пример | качество сортировки для медианы | эффективные алгоритмы медианы |
| поиск медианы в больших данных | использование разделения для медианных вычислений | сложность поиска медианы | лучшие практики сортировки для аналитики | как выбрать алгоритм для медианы |
| алгоритмы поиска медианы в Python | использование встроенной сортировки | быстрый поиск медианы | линейная сортировка для медианы | методы быстрой выборки |
| подготовка данных для медианы | преимущества quickselect | стратегии для поиска медианы | примеры сортировки для медианы | разделение данных для медианных расчетов |