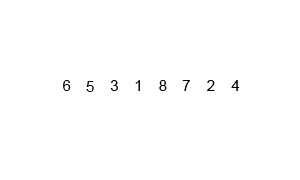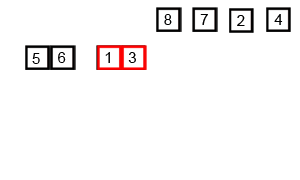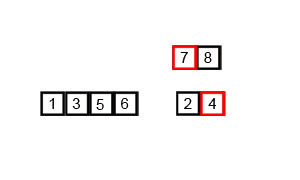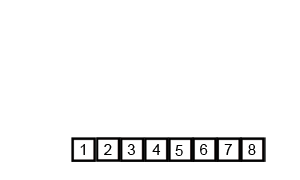
Магия сортировки и кеширования: как Merge Sort превращает обработку данных в скорость света
В современном мире обработки данных скорость и эффективность алгоритмов играют ключевую роль․ Когда мы сталкиваемся с большими объемами информации, простое выполнение сортировки перестает быть достаточно быстрым, а требования к быстродействию только растут․ В этой статье мы расскажем о том, как алгоритм Merge Sort помогает достигать высокой скорости сортировки, а вместе с ним — о важности кеширования и его роли в повышении производительности․ Мы разберем, как эти два понятия связаны и почему их совместное использование изменяет подход к работе с большими массивами данных․
Что такое Merge Sort и зачем он нужен?
Merge Sort, это один из классических алгоритмов сортировки, основанный на принципе «разделяй и властвуй»․ Его отличительная особенность — это рекурсивное разбиение массива на меньшие части до состояния, когда каждая часть содержит лишь один или два элемента, после чего происходит последовательное слияние отсортированных массивов․ Этот алгоритм обладает рядом преимуществ:
- Стабильность: Merge Sort сохраняет порядок равных элементов․
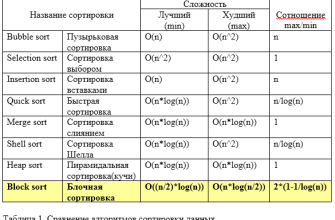
- Сложность: Средняя и худшая сложность — O(n log n), что делает его пригодным для работы с очень большими объемами данных․
- Предсказуемость: Его поведение не зависит от исходного порядка данных, что позволяет легко планировать ресурсы․
Несмотря на свои преимущества, Merge Sort требует дополнительной памяти для временных массивов, что в некоторых случаях может стать критичным фактором․ Однако благодаря своей структуре он отлично подходит для реализации в системах, где важна стабильность и предсказуемое время выполнения․
Механизм работы Merge Sort: шаг за шагом
Разделение массива на части
Сам процесс начинается с рекурсивного деления исходного массива на две половины․ Эти половинки далее делятся между собой, пока не достигнут уровень, когда части станут очень малыми — обычно это массивы из одного элемента․ В этот момент можно сказать, что массив разделен до минимальных частей․
Объединение и сортировка
Затем происходит этап слияния — объединение двух отсортированных частей в один большой отсортированный массив․ Этот процесс продолжается до тех пор, пока не восстановится исходная структура с отсортированными данными․ Каждое слияние сортирует элементы, сравнивая их между собой, обеспечивая, чтобы конечный массив был упорядочен․
| Шаг | Действия | Результат |
|---|---|---|
| 1 | Деление массива на половины | Массив разбит на две части |
| 2 | Рекурсивное деление каждоой части | Достигли частей из одного элемента |
| 3 | Слияние двух элементов в отсортированный массив | Обратное склеивание, получаем отсортированные пары |
| 4 | Продолжаем слияние на шаге вверх по рекурсии | Получаем отсортированные большие массивы |
| 5 | Объединение всех частей в окончательный отсортированный массив | Полная сортировка завершена |
Кеширование и его роль в ускорении Sort
Теперь перейдем к важному аспекту — кешированию․ Современные процессоры и операционные системы используют кеши для хранения часто используемых данных, что значительно ускоряет доступ к ним․ Когда алгоритмы работают с большими объемами данных, правильное использование кеша позволяет минимизировать обращения к медленной основной памяти, максимально используя быстрый кеш․
Применительно к Merge Sort, эффективное кеширование проявляется в нескольких направлениях:
- Локальность данных: Разделение и объединение массивов происходит последовательно, что способствует сохранению данных в кешах․
- Оптимизация доступа: Четкое планирование обращения к памяти позволяет алгоритму быстрее работать за счет минимизации промахов кеша․
- Использование буферных массивов: Эффективное управление временными массивами делает работу алгоритма более полезной для кеша․
Почему кеширование так важно?
При работе с огромными массивами простое обращение к данным в основной памяти может занять сотни или тысячи тактов процессора․ В то время как кеш — это быстрый буфер, который обеспечивает доступ к часто используемым данным почти мгновенно․ Если алгоритм хорошо “настроен” под работу с кешем, даже большие объемы обрабатываемых данных не станут узким местом․
Корректное использование кеширования способствует ускорению алгоритма во много раз, превращая потенциально долгую операцию в очень быструю․ Особенно это важно в задачах реального времени и системах, где задержки недопустимы․
Практические советы по оптимизации Merge Sort с учетом кеширования
Чтобы максимально извлечь пользу из кеширования при реализации Merge Sort, следует соблюдать ряд рекомендаций:
- Использовать встроенные функции и библиотеки: Многие современные языки и библиотеки уже оптимизированы под кеширование․
- Минимизировать количество выделений памяти: Выделять временные массивы один раз и переиспользовать их, избегая частых операций malloc/free․
- Оптимизация порядка обращения к данным: Следить за тем, чтобы последовательность чтения и записи была линейной, избегая лишних скачков․
- Производить мелковременный разбор: Разделение и слияние лучше выполнять так, чтобы данные оставались в кешах как можно дольше․
Также можно использовать различные техники, такие как тюнинг размера буфера или внедрение специфичных стратегий для работы с конкретными видами данных, чтобы максимально эффективно использовать кеш памяти․
Комбинирование Merge Sort и кеширования: конечный результат
Объединение всех этих аспектов позволяет создавать системы и алгоритмы, которые работают с огромными объемами данных стремительно и эффективно․ Merge Sort, будучи классическим примером стабильной сортировки с предсказуемой сложностью, при правильной настройке и оптимизации под кеш становится еще более мощным инструментом․ В итоге, мы получаем алгоритм, который не только работает быстро на теоретическом уровне, но и использует аппаратные возможности на практике максимально полно․
Самое важное — понимание, что эффективность работы алгоритма во многом определяется правильно подобранными стратегиями работы с памятью и системной архитектурой․ Технологии растут, и умение использовать кеширование с Merge Sort дает нам преимущество в обработке данных в реальных условиях․
Вопрос: Почему использование кеширования при реализации Merge Sort так важно для обработки больших данных?
Подробнее
| эффективное кеширование merge sort | оптимизация скорости сортировки | ускорение больших данных | кеш и алгоритмы | умное использование памяти |
| как кеширование помогает Merge Sort | советы по оптимизации for big data | стратегии ускорения сортировки | структура данных и кеш | примеры и техники |
| почему важно кешировать при делении массивов | как уменьшить промахи кеша | ускорение обработки данных | управление памятью в алгоритмах | современные технологии и подходы |