Мастерство анализа сложности алгоритмов сортировки: разбираемся в нотации «Большое О»
Когда мы начинаем изучать программирование и алгоритмы, рано или поздно сталкиваемся с понятием оценки эффективности — насколько быстро или медленно работает тот или иной алгоритм․ Одним из важнейших инструментов для этого является нотация «Большое О»․ Именно она позволяет нам количественно сравнивать различные подходы к решению задач, понять, какой алгоритм подходит для определенных условий, и оптимизировать наши программы․ В этой статье мы подробно разберемся, что такое сложность алгоритмов сортировки, как она выражается через нотацию «Большое О» и почему это так важно в практике․
Что такое нотация «Большое О» и зачем она нужна
Нотация «Большое О» (O-нотация) — это математическая формула, которая описывает асимптотическую сложность алгоритма․ Она показывает, как изменение размера входных данных влияет на время выполнения или объем используемой памяти․ Это своего рода картограмма, позволяющая «увидеть в будущем», как будет вести себя алгоритм при очень больших объемах данных․
Например, если у нас есть алгоритм сортировки, который работает за некоторое число операций, пропорциональное размеру массива данных, уменьшение времени выполнения при увеличении объема информации можно представить как функцию․ И именно нотация «Большое О» позволяет выразить эту функцию в виде максимально возможной оценки:
Наиболее общий вид: O(функция)
Основная идея — обозначить верхнюю границу затрат времени или ресурсов, которая может существенно отличаться для различных алгоритмов․ Чем короче формула, тем лучше — ведь она подчеркивает асимптотическую сложность, которая не учитывает мелкие детали, а показывает наиболее важные показатели․
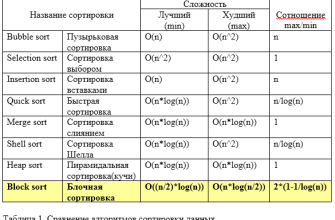
Типовые сложности алгоритмов сортировки
Простые алгоритмы сортировки
Это базовые методы, которые обычно используются для понимания принципов сортировки и обучения основам алгоритмизации․ Они характеризуются следующими сложностями:
- Пузырьковая сортировка (Bubble Sort):
O(n^2) — квадратичная сложность․ Идеально подходит для небольших массивов, но при росте данных становится очень медленной․ - Сортировка выбором (Selection Sort):
O(n^2) — также квадратичная, схожа по эффективности с пузырьковой сортировкой․ - Сортировка вставками (Insertion Sort):
O(n^2) — особенно эффективна на уже почти отсортированных массивах, но при больших объемах работает медленно․
Более эффективные алгоритмы
Для больших объемов данных используют более сложные, но и более быстрые методы:
- Быстрая сортировка (Quick Sort):
O(n log n) — средняя сложность, наиболее популярный благодаря своей эффективности и универсальности․ - Сортировка слиянием (Merge Sort):
O(n log n) — стабильна и работает независимо от начального порядка элементов․ - Пирамидальная сортировка (Heap Sort):
O(n log n) — использует структуру данных «куча» для сортировки․
Важно отметить, что эти алгоритмы отличаются по поведению при разных условиях, и их выбор зависит от конкретной задачи и требований․
Разбор «в худшем», «в среднем» и «в лучшем» случаях
Что означает «худший случай»?
Худший случай — это ситуация, когда алгоритм сталкивается с наихудшей возможной последовательностью входных данных․ Для сортировки этот сценарий обычно означает, что данные уже отсортированы в обратном порядке или содержат множество одинаковых элементов, которые усложняют процесс сортировки;
Что подразумевается под «лучшим случаем»?
Лучший случай, это ситуация, когда алгоритм работает максимально эффективно․ В случае с сортировкой это может означать, что данные уже отсортированы или майже отсортированы, и алгоритм не тратит лишнее время на обработку;
Общий принцип: почему важно учитывать все случаи
Знание о сложности в разных сценариях помогает выбрать наиболее подходящий алгоритм для конкретной ситуации․ Например, при небольшом объеме данных можно использовать простые методы, а при больших — уже эффективные слияние или быструю сортировку․ Также это позволяет понять, насколько условно оптимальным или рискованным будет использование того или иного метода в условиях реальных задач․
Практическое сравнение алгоритмов сортировки в таблице
| Алгоритм | Лучший случай | Средний случай | Худший случай | Дополнительные заметки |
|---|---|---|---|---|
| Пузырьковая сортировка | O(n) | O(n^2) | O(n^2) | Медленный, но легко реализуемый․ |
| Быстрая сортировка | O(n log n) | O(n log n) | O(n^2) | Самый распространенный, зависит от выбора опорного элемента․ |
| Сортировка слиянием | O(n log n) | O(n log n) | O(n log n) | Стабильна, требует дополнительной памяти․ |
| Пирамидальная сортировка | O(n log n) | O(n log n) | O(n log n) | Эффективна, универсальна, но сложнее в реализации․ |
Общий принцип оценки сложности алгоритмов — это понимание их поведения в разных сценариях и способность предвидеть ресурсы, необходимые для обработки больших данных․ Нотация «Большое О» — это мощный инструмент для этого, позволяющий вам сделать обоснованный выбор метода сортировки в конкретных условиях․ Чем лучше вы понимаете, как работает тот или иной алгоритм, тем эффективнее сможете писать программы и оптимизировать их работу․
Важно помнить, что даже самый быстрый алгоритм в теории не всегда подходит для специфичных задач или ограниченных ресурсов․ Поэтому при выборе метода сортировки необходимо учитывать также такие факторы, как стабильность, занимая память, простота реализации и особенности данных․
Вопрос к статье
Какие алгоритмы сортировки лучше всего подходят для обработки больших объемов данных и почему?
Ответ: Для обработки больших объемов данных лучше всего подходят такие алгоритмы, как слияние сортировки (Merge Sort) и пирамидальная сортировка (Heap Sort)․ Они имеют сложность O(n log n) во всех случаях, что обеспечивает стабильную производительность независимо от начальной последовательности данных․
Обычно Merge Sort предпочтителен, так как он стабильный и хорошо работает с очень большими объемами, особенно при использовании внешней памяти (например, при сортировке данных на жестком диске)․ Важе Heap Sort — это отличный вариант, когда важна минимизация дополнительной памяти, поскольку он не требует дополнительных структуры данных и работает с постоянными затратами целей․
Подробнее
| Тип | Особенности | Лучшее применение | Недостатки | Примеры использования |
|---|---|---|---|---|
| Merge Sort | Стабильная, занимается с большими данными, использует дополнительную память | Внешняя сортировка, большие базы данных | Требует дополнительной памяти, медленнее внутренней сортировки при небольших данных | Обработка файловых данных, базы данных |
| Heap Sort | Эффективная по памяти, не требует дополнительных структур данных | Встроенные системы, где важна минимизация памяти | Меньшая стабильность, может уступать по скорости на практике | Внутренняя сортировка массивов |
| Quick Sort | Высокая эффективность, зависит от выбора опорного элемента | Общая сортировка внутри программ | Плохое поведение при плохом выборе опорного элемента, худший случай O(n^2) | Стандартизированные библиотеки, быстрая сортировка в приложениях |