Невероятная эффективность Bucket Sort: Распределение для быстрой сортировки
В нашем мире, где данные становятся важнейшим ресурсом, умение эффективно их сортировать играет ключевую роль в различных областях, от научных исследований до повседневной жизни. Мы все сталкиваемся с необходимостью упорядочивания информации, будь то числа, строки или какие-либо другие структуры данных. В этой статье мы подробно рассмотрим алгоритм Bucket Sort, который демонстрирует удивительную эффективность в распределении и сортировке данных. Давайте погрузимся в эту тему!
—
Что такое Bucket Sort?
Bucket Sort — это алгоритм сортировки, который использует метод распределения значений по "ведрам" для последующей сортировки этих значений. Он хорошо подходит для сортировки элементов, которые равномерно распределены по промежутку, и часто оказывается эффективнее по сравнению с более традиционными методами сортировки, такими как Quick Sort или Merge Sort, в определённых условиях.
Основная идея заключается в том, чтобы разбить массив на несколько "ведер", в каждом из которых хранится подмассив. Затем каждый подмассив сортируется отдельно, и в конце все они объединяются. Это позволяет значительно ускорить процесс сортировки, особенно в случае, если данные можно разбить на равномерные интервалами.
—
Как работает Bucket Sort?
Принцип работы алгоритма довольно просто. Мы можем разбить процесс на несколько ключевых этапов:
- Создание "ведер": Мы определяем количество ведер в зависимости от диапазона входных данных.
- Распределение: Каждый элемент массива помещается в соответствующее ведро.
- Сортировка ведер: Содержимое каждого ведра сортируется отдельно, с использованием любой другой сортировки, например, Insertion Sort.
- Слияние: Все отсортированные ведра объединяются в один массив.
Звучит просто, не так ли? Давайте рассмотрим более детально каждый из этих этапов.
—
Этап 1: Создание ведер
При создании ведер важно учесть, сколько всего мы планируем их использовать. Мы часто выбираем это количество, исходя из размера данных и диапазона их значений. Например, для массива, содержащего числа от 0 до 100, можно создать 10 ведер, каждое из которых будет охватывать диапазон по 10 элементов (0-9, 10-19 и т.д.).
—
Этап 2: Распределение
На этом этапе мы проходим по каждому элементу исходного массива и определяем, в какое ведро он должен быть помещен. Это можно сделать с помощью простой формулы:
index = (value ― min) / interval
Здесь min — минимальное значение в массиве, а interval — величина, на которую мы разбиваем диапазон.
—
Этап 3: Сортировка ведер
Как только все элементы будут распределены по ведрам, мы сортируем каждый подмассив внутри ведер. Это может быть выполнено с помощью любого стандартного алгоритма сортировки, но наилучшие результаты показывают алгоритмы, которые являются более оптимальными для малых массивов, такие как Insertion Sort.
—
Этап 4: Слияние
Когда все ведра отсортированы, мы объединяем их содержимое в один массив. Этот шаг также довольно прост, и он завершается слиянием элементов из каждого ведра, создавая полную отсортированную последовательность.
—
Преимущества и недостатки Bucket Sort
Как и любой другой алгоритм, Bucket Sort имеет свои сильные и слабые стороны. Давайте подробнее рассмотрим их.
| Преимущества | Недостатки |
|---|---|
| Высокая эффективность при равномерно распределённых данных. | Зависимость от размера диапазона данных. |
| Может быть быстрее, чем другие алгоритмы сортировки, на больших объёмах данных. | Неэффективен при малом числе данных. |
| Легко реализуемый и понятный алгоритм. | Требует больше памяти для хранения дополнительных ведер. |
—
Примеры применения Bucket Sort
Результаты работы алгоритма можно наблюдать в различных прикладных задачах. Давайте рассмотрим несколько примеров, где Bucket Sort находит широкое применение:
- Сортировка больших объёмов данных с равномерным распределением, например, в статистических обработках.
- Обработка изображений, где данные цветов могут быть распределены по определённому диапазону.
- Системы управления базами данных, где необходимо индексировать и упорядочивать записи.
- Анализ финансовых данных, где требуется быстрая сортировка значений акций или прочих активов.
—
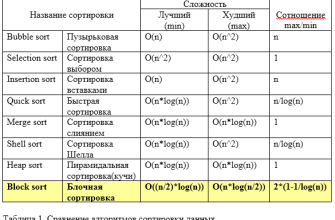
Сложность и производительность Bucket Sort
Оценка производительности алгоритма Bucket Sort зависит от нескольких факторов, включая количество ведер и характер входных данных. В лучшем случае, когда данные равномерно распределены, сложность алгоритма составляет O(n + k), где n — это количество элементов, а k — количество ведер. Однако в худшем случае, если данные неравномерно распределены, сложность может возрасти до O(n^2). Это подчеркивает важность правильного выбора количества ведер и их границ.
—
Реализация Bucket Sort на Python
Теперь, когда мы разобрали теоретические аспекты, давайте посмотрим, как реализовать Bucket Sort на практике. Вот простой пример на Python:
def bucket_sort(array): if not array: return array # Найдем максимальное и минимальное значение min_value, max_value = min(array), max(array) # Определим диапазон bucket_range = (max_value ― min_value) // len(array) + 1 buckets = [[] for _ in range(bucket_range)] # Распределим элементы по ведрам for num in array: buckets[(num — min_value) // bucket_range].append(num) # Сортируем каждое ведро и объединяем sorted_array = [] for bucket in buckets: sorted_array.extend(sorted(bucket)) return sorted_arrayПример использования
data = [4, 3, 2, 1, 5, 3, 5, 1] print(bucket_sort(data))
Как видно из кода, алгоритм достаточно прост в реализации и понятен.
—
Каковы основные условия, при которых Bucket Sort будет наиболее эффективным?
Основные условия:
- Равномерное распределение данных: Алгоритм работает лучше, когда данные равномерно распределены по диапазону.
- Большое количество данных: Эффективность увеличивается с ростом объёма данных, так как это позволяет лучше использовать свои возможности.
- Известные границы: Если известны минимальное и максимальное значения входных данных, это значительно упрощает процесс создания ведер.
—
Подробнее
| Алгоритмы сортировки | Оптимизация производительности | Программирование на Python | Статистический анализ данных | Эффективные алгоритмы |
| Сложность алгоритмов | Параллельная сортировка | Визуализация данных | Практика программирования | Сортировка массивов |