Параллельные алгоритмы сортировки: как ускорить обработку больших данных
В современном мире объемы данных увеличиваются в геометрической прогрессии, и обработка информации становится одной из важнейших задач для специалистов в области программирования и вычислительной техники. Одним из ключевых решений для повышения эффективности работы с большими массивами данных является использование параллельных алгоритмов сортировки. В этой статье мы подробно разберемся, что такое параллельные алгоритмы сортировки, как они работают, какие преимущества и недостатки имеют, а также познакомимся с наиболее популярными методами.
Что такое параллельные алгоритмы сортировки?
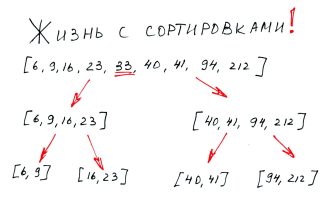
Параллельные алгоритмы сортировки — это разновидность методов, предназначенных для выполнения сортировки данных одновременно несколькими потоками или процессами, что значительно ускоряет общий процесс обработки. В отличие от последовательных алгоритмов, где сортировка выполняется поэлементно один за другим, параллельные алгоритмы разделяют исходный массив на части, которые сортируются независимо и одновременно.
Главная идея заключается в использовании возможностей многопроцессорных систем или кластеров для распределения вычислительной нагрузки, что позволяет сократить время выполнения и повысить производительность при работе с большими объемами данных.
Основные принципы работы параллельных алгоритмов
Параллельные алгоритмы основаны на нескольких ключевых принципах:
- Разделение данных: массив делится на части, которые обрабатываются независимо друг от друга;
- Распараллеливание задач: выполнение нескольких операций одновременно;
- Синхронизация результатов: объединение отсортированных частей в финальный массив.
Рассмотрим иллюстрацию этого процесса:
| Этап | Описание |
|---|---|
| Деление массива | Исходный массив разбивается на части, которые далее сортируются отдельно. |
| Параллельная сортировка | Каждая часть сортируется одновременно несколькими потоками или процессами. |
| Объединение результатов | Отсортированные части объединяются с помощью специальных алгоритмов, например, слияния. |
Преимущества параллельных алгоритмов
- Значительное сокращение времени выполнения сортировки, особенно при работе с большими данными;
- Эффективное использование ресурсов современного многоядерного и многопроцессорного оборудования;
- Возможность обработки в реальном времени информации, которая раньше требовала значительных затрат времени.
Недостатки и сложности реализации
- Сложность в реализации и отладке таких алгоритмов, особенно при синхронизации потоков;
- Неравномерное распределение нагрузки, что может уменьшить эффективность;
- Проблемы с конкуренцией за ресурсы и возможными блокировками при работе с разделяемой памятью.
Обзор популярных параллельных алгоритмов сортировки
Параллельное сортировка слиянием (Parallel Merge Sort)
Это один из наиболее распространенных и эффективных методов для реализации параллельной сортировки. Он основывается на классическом алгоритме сортировки слиянием, но выполняется в многопоточном режиме.
- На первой стадии осуществляется последовательное деление массива на меньшие части;
- Затем данные сортируются в несколько потоков — каждый занимается своей частью;
- Объединение отсортированных частей происходит через очередь слияния.
Вопрос: Чем отличается параллельное сортировка слиянием от классической?
Параллельное слияние разделяет задачу на части, которые сортируются одновременно, тогда как классическая — выполняет сортировку последовательно. Такой подход существенно ускоряет обработку больших объемов данных, особенно в системах с несколькими ядрами.
Параллельная сортировка быстрого алгоритма (Parallel QuickSort)
Этот метод применяется как к классической, так и к адаптированным версиям быстрой сортировки. Основная идея — разделение массива по опорному элементу на части, которые сортируются независимо в разных потоках.
- В каждом потоке выбирается свой опорный элемент;
- Деление и рекурсивное выполнение происходит одновременно;
- Результаты объединяются для получения финально отсортированного массива.
Преимущество заключается в высокой скорости работы, особенно для неравномерных данных.
Параллельная сортировка быстрой сортировки с использованием разделяемых очередей и потоков
Этот подход реализует управление задачами через очереди задач, что обеспечивает более стабильное распределение нагрузки. Кроме того, он легок в масштабировании и позволяет гибко управлять потоками.
Практические примеры и применение
Реальные сценарии использования параллельных алгоритмов
Параллельные алгоритмы сортировки находят широкое применение в следующих областях:
- Обработка больших данных в системах аналитики и бизнес-аналитике;
- Обработка изображений и видео, где требуется высокая скорость обработки;
- Научные вычисления, моделирование и симуляции;
- Облачные сервисы и распределенные вычислительные системы.
Кейс: ускорение обработки данных в финансовом секторе
В финансовых институтах ежедневная обработка огромных объемов транзакций и сделок требует максимальной скорости и надежности. Использование параллельных алгоритмов сортировки позволяет не только снизить временные затраты, но и обеспечить своевременную реакцию на рыночные изменения. Например, сортировка огромных массивов ценовых данных для построения аналитических отчетов выполняется в считаные минуты вместо часов.
Практическая рекомендация:
- Используйте многопоточность и распараллеливание для обработки больших массивов данных;
- Следите за балансировкой нагрузки между потоками для обеспечения максимальной эффективности;
- Обеспечьте корректную синхронизацию данных для избежания ошибок.
Параллельные алгоритмы сортировки — это мощный инструмент, который позволяет значительно ускорить работу с большими массивами данных. Однако их реализация требует понимания принципов работы многопоточности и особенностей современных вычислительных систем. Для начинающих рекомендуется начинать с простых алгоритмов, таких как параллельное слияние, и постепенно осваивать более сложные методы.
Главное, не бояться экспериментировать и тестировать эффективность реализованных решений. Современные языки программирования и библиотеки значительно упрощают задачу, предоставляя готовые инструменты для работы с потоками и асинхронностью.
Вопрос: Какие основные преимущества использования параллельных алгоритмов сортировки по сравнению с последовательными?
Основные преимущества, это существенное сокращение времени выполнения операций благодаря одновременной обработке данных, эффективное использование современных многоядерных систем, а также возможность работы с очень крупными массивами данных, обработка которых в традиционном режиме занимала бы часы или дни.
Обзор LSI-запросов по теме
Подробнее
| Параллельная сортировка больших данных | Методы распараллеливания сортировки | Алгоритмы многопоточечной сортировки | Оптимизация параллельных алгоритмов | Использование многопроцессорных систем |
| Преимущества параллельных алгоритмов | Недостатки параллельных сортировок | Обработка больших массивов данных | Примеры из практики | Современные библиотеки и инструменты |