Погружение в мир поразрядной сортировки: обработка символов и эффективные алгоритмы
Когда мы говорим о классических алгоритмах сортировки‚ на ум приходят такие знакомые имена‚ как быструю сортировку‚ сортировку слиянием или пузырьковую сортировку. Однако существует одна техника‚ которая широко используется в специальных случаях — поразрядная сортировка. Ее уникальность заключается в том‚ что она работает с разрядами элементов‚ а не с целыми объектами целиком‚ что позволяет эффективно сортировать большие объемы данных‚ особенно если речь идет о строках и символах. В этой статье мы подробно разберем принцип работы поразрядной сортировки‚ сфокусируемся на обработке символов‚ а также опишем наиболее распространенные вариации этого метода.
Что такое поразрядная сортировка и зачем она нужна?
Поразрядная сортировка, это техника сортировки‚ которая осуществляется по отдельным разрядам элементов. В отличие от стандартных методов‚ она обрабатывает данные по компонентам‚ начиная с младшего разряда и двигаясь к старшему. Такая стратегия эффективна для сортировки строк‚ чисел и специальных структур данных‚ где знаки‚ символы или разряды играют ключевую роль в порядке элементов.
Главная задача — упорядочить данные по символам или цифрам‚ начиная с самого младшего разряда (например‚ последнего символа в строке) и продвигаясь к более значимым. Благодаря этому подходу алгоритм достигает высокой скорости и стабильности‚ особенно при правильной реализации и использовании вспомогательных структур данных.
Что делает поразрядную сортировку уникальной? Почему она предпочтительнее в определенных случаях?
Ответ: Поразрядная сортировка особенно эффективна при обработке больших объемов строк или чисел‚ где данные имеют фиксированный или предсказуемый диапазон символов или разрядов. Она быстро работает‚ так как не требует сравнения элементов целиком‚ а манипулирует отдельными разрядами‚ что значительно ускоряет процесс по сравнению с более традиционными алгоритмами сортировки. В частности‚ она отлично справляется с задачами‚ связанными с сортировкой слов‚ номеров‚ дат или других последовательностей‚ где порядок определяется по отдельным составляющим.
Обработка символов и тонкости реализации
При работе с символами важно учитывать их кодировку. Самая распространенная — ASCII‚ где каждый символ представлен числовым кодом. Например‚ строчные буквы от ‘a’ до ‘z’ имеют коды от 97 до 122‚ заглавные — от 65 до 90. В более современных системах зачастую используют Unicode‚ расширяющий диапазон и обеспечивающий поддержку множества языков и символов.
Для реализации поразрядной сортировки при обработке символов нами важно определить диапазон символов‚ с которыми работаем‚ чтобы правильно выбрать порядок обработки разрядов.
Пример: сортировка строк по алфавиту (ASCII)
- Определяем диапазон символов‚ например‚ для строчных английских букв — от 97 до 122.
- На каждом этапе алгоритма выбираем текущий разряд — это конкретный символ в строке.
- Создаем вспомогательные структуры‚ например‚ счетчики для подсчета частоты каждого символа.
- Формируем новую упорядоченную последовательность согласно итогам по текущему разряду.
- Переходим к следующему разряду — следующему символу в строке‚ и повторяем процедуру‚ пока все разряды не будут обработаны.
| Этап | Действие | Описание |
|---|---|---|
| Инициализация | Выбор диапазона символов | Определяется диапазон кодов символов‚ с которыми будем работать. |
| Обработка разряда | Подсчет частот | Производится подсчет количества каждого символа на текущем разряде. |
| Создание нового порядка | Перестановка элементов | На основе подсчитанных данных формируется новая упорядоченная последовательность. |
| Переход к следующему разряду | Обработка следующего символа | Процесс повторяется для следующего разряда‚ пока не обработаны все символы. |
Обработка символов требует аккуратности при выборе диапазона и обработки специальных символов‚ таких как табуляция‚ пробелы или знаки пунктуации. В зависимости от задачи можно подстроить алгоритм под конкретные требования.
Особенности реализации и оптимизации
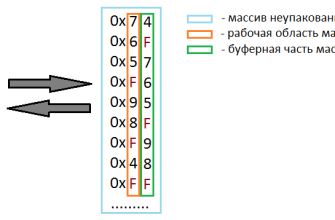
Реализация поразрядной сортировки‚ особенно при работе со строками‚ может в точности зависеть от выбранных методов подсчета и структур данных. Одним из ключевых моментов является использование буферных массивов‚ в которых формируется итоговая последовательность‚ а также оптимизация побитовых операций для ускорения работы с символами.
Кроме классического подхода‚ существует несколько вариантов реализации‚ наиболее популярные из которых:
- Counting sort — подсчет частот и перестановка элементов по итогу;
- Radix sort — многократное применение поразрядной сортировки с обработкой разрядов от младшего к старшему.
Для повышения эффективности стоит учитывать:
- Использование стабильных алгоритмов: важно сохранить порядок элементов с одинаковыми символами между итерациями.
- Минимизация дополнительных затрат памяти: аккуратно управлять буферами и счетчиками.
- Учет кодировки символов: работать в диапазонах‚ устраняющих необходимость обработки дубликатов или лишних символов.
Пример оптимизированной реализации на Python
def counting_sort_for_characters(arr‚ index): max_char_code = 255 # для ASCII‚ можно менять под Unicode count = [0] * (max_char_code + 1) output = ["" for _ in range(len(arr))] for string in arr: char_code = ord(string[index]) if index < len(string) else 0 count[char_code] += 1 for i in range(1‚ len(count)): count[i] += count[i ⎻ 1] for string in reversed(arr): char_code = ord(string[index]) if index < len(string) else 0 count[char_code] -= 1 output[count[char_code]] = string return output
Такое решение позволяет сортировать строки по определенному разряду эффективно и стабильно‚ что важно для последовательного выполнения алгоритма поразрядной сортировки по всей длине строки.
Примеры использования и реальный опыт
На практике поразрядная сортировка применяется в различных сферах‚ где требуется эффективная обработка больших массива данных. Среди них:
- Обработка строковых данных: сортировка больших списков имен‚ городов‚ или других текстовых данных.
- Сортировка чисел фиксированной длины: номера телефонов‚ коды продуктов‚ серийные номера.
- Обработка дат и временных меток: упорядочивание логов по времени‚ обработка временных кодов.
Множество системных решений используют именно этот алгоритм‚ чтобы снизить время выполнения при обработке миллионах элементов. Например‚ в системах поиска и индексирования‚ где сортировка строк и символов — одна из ключевых операций.
Исторически сложилось так‚ что поразрядная сортировка считается одним из самых быстрых алгоритмов для конкретных задач‚ связанных с упорядочиванием строк и символов.
Общаясь с алгоритмами сортировки‚ мы часто встретимся с подходами‚ которые требуют специальных знаний и умений. Поразрядная сортировка, это мощный инструмент‚ который‚ при правильной настройке и понимании‚ способен значительно ускорить обработку данных. Важнейшие моменты при ее использовании — это учет диапазона символов‚ стабильность сортировки и оптимизация скорости работы.
Для тех‚ кто только начинает изучать этот алгоритм‚ рекомендуется экспериментировать с разными наборами данных‚ учитывать особенности их структуры и систематически тестировать эффективность реализации. Такой подход поможет глубже понять преимущества и ограничения поразрядной сортировки в реальных задачах.
Обязательно попробуйте реализовать алгоритм самостоятельно!
Реальные практические навыки приходят с практикой. Берите пример кода‚ меняйте диапазоны‚ добавляйте поддержку Unicode и экспериментируйте с данными разных типов – так вы станете настоящим экспертом в области эффективных алгоритмов сортировки.
Какие преимущества и недостатки имеет поразрядная сортировка по сравнению с классическими методами?
Ответ: Среди ключевых преимуществ поразрядной сортировки — высокая скорость при работе с фиксированными длинами элементов и возможность обработки больших объемов данных‚ особенно строк и числовых кодов‚ без необходимости сравнения всех элементов полностью. Она является стабильной‚ легко реализуемой и масштабируемой при правильной оптимизации. Основные недостатки — ограниченность в гибкости (например‚ сложность при переменной длине строк)‚ высокая зависимость от диапазона символов‚ а также необходимость временных буферов‚ что увеличивает требования к памяти.