Полное руководство по сортировке Counting Sort для строк: как быстро и эффективно упорядочить текстовые данные
В современном мире обработки данных и программирования поиск эффективных алгоритмов сортировки становится особенно актуальным. Вы когда-нибудь сталкивались с задачей сортировки большого объема текстовой информации — строк, которые необходимо упорядочить по алфавиту или по другим признакам? Тогда метод Counting Sort, хотя и изначально предназначенный для числовых данных, может стать неожиданно полезным инструментом для работы со строками. В этой статье мы подробно расскажем, как применить алгоритм Counting Sort к строкам, разберем все этапы, сложности и тонкости реализации, а также дадим практические рекомендации для программистов и аналитиков.
Что такое Counting Sort и почему его используют для строк?
Counting Sort, это стабильный алгоритм сортировки, который работает по принципу подсчета количества вхождений каждого элемента. Изначально его применяли для сортировки чисел, потому что он отлично проявляет себя на небольших диапазонах, позволяя сортировать за линейное время. Однако, при правильной адаптации, его можно использовать и для строк, особенно если мы располагаем ограниченным алфавитом и хотим быстро упорядочить массив строк по определенному признаку.
Почему именно Counting Sort? Его преимущества заключаются в высокой эффективности при ограниченном диапазоне значений и стабильности. Это значит, что при сортировке строк по алфавиту или по первому символу, мы можем добиться очень быстрой работы, сохранив порядок строк с одинаковыми ключами. Но для этого необходимо правильно подготовить данные и реализовать алгоритм с учетом особенностей строковых данных.
Подготовка данных для применения Counting Sort к строкам
Для того чтобы успешно использовать Counting Sort для строк, мы должны учитывать несколько важных аспектов. Во-первых, необходимо определить диапазон ключей — то есть, по чему мы собираемся сортировать наши строки. Обычно сортируют по первому символу, по всему слову или по определенной позиции в строке. Варианты зависят от задачи и типа данных.
Во-вторых, нужно убедиться, что все строки приведены к одному формату и имеют одинаковую длину или обработаны с учетом длины. Например, при сортировке по первому символу достаточно выбрать только этот символ для каждого слова, а при сортировке по всей строке — обеспечить одинаковую длину, добавляя условные символы заполнения.
Рассмотрим основные методы подготовки данных:
- Выбор ключа: определение позиции в строке, по которой будем сортировать (от начала или с конца).
- Форматирование строк: добавление ведущих или завершающих символов для выравнивания длин.
- Определение диапазона: знание минимального и максимального символа в алфавите, чтобы создать массив подсчета.
Реализация Counting Sort для строк: пошаговое руководство
Теперь перейдем к практическому разбору алгоритма. Предположим, у нас есть массив строк, и мы собираемся отсортировать их по алфавиту, основываясь на первом символе каждой строки. Ниже приводится развернутая последовательность действий и пример кода, который поможет реализовать этот подход.
Шаг 1: выбираем алфавит и определяем диапазон
В качестве примера возьмем английский алфавит в нижнем регистре: от ‘a’ до ‘z’. Тогда диапазон символов, 26. Это значительно упрощает задачу.
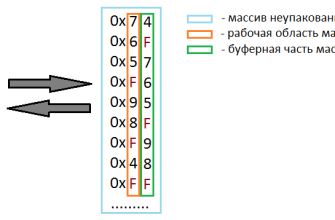
Шаг 2: подготовка массива подсчета
Создаем массив длиной 26, где каждый элемент считает количество строк, начинающихся с соответствующего символа.
Шаг 3: подсчет вхождений
Проходим по всем строкам и увеличиваем счетчик в массиве для первого символа каждой строки.
Шаг 4: создание префиксных сумм
Обрабатываем массив подсчета, чтобы получить позиции вставки для каждого ключа.
Шаг 5: сортировка и сборка результата
Проходим по исходному массиву строк и вставляем каждую строку в итоговую последовательность по индексу, полученному из массива подсчета. Не забываем уменьшать подсчет после каждого вставления для обеспечения стабильности.
Рассмотрим пример на практике:
| исходный массив | отсортированный массив |
|---|---|
["apple", "banana", "apricot", "blueberry", "avocado"] | ["apple", "apricot", "avocado", "banana", "blueberry"] |
Особенности и ограничения Counting Sort для строк
Несмотря на свои преимущества, метод Counting Sort имеет определенные ограничения, которые важно учитывать при работе с текстовыми данными.
- Зависимость от диапазона символов: если ваш текст использует широкий диапазон символов (например, юникод), создание массива подсчета становится неэффективным или невозможным.
- Длина строк: при больших длинах и разнообразии символов сортировка по всей длине становится затратной по времени и памяти.
- Не подходит для переменной длины без предварительной обработки: чтобы сохранять стабильность и корректность, необходимо привести все строки к одинаковой длине или сортировать по соответствующим позициям с учетом вариаций.
- Время и память: несмотря на линейную сложность, при очень большом диапазоне символов объем массива подсчета может стать непрактичным.
Практические советы и рекомендации при реализации Counting Sort для строк
Чтобы максимально эффективно использовать Counting Sort для строк, важно соблюдать несколько рекомендаций:
- Определяйте диапазон символов заранее: это значительно упрощает настройку массива подсчета и улучшает скорость работы.
- Учитывайте регистр и язык текста: при необходимости приводите строки к нижнему регистру или используйте специальный алфавит.
- Обратите внимание на стабильность: алгоритм должен сохранять порядок равных элементов — это важно для многоступенчатой сортировки.
- Используйте для длинных строк другие алгоритмы: для длинных текстов более подходящими будут сравнительные алгоритмы, такие как сортировка с учетом длины или radix sort.
- Оптимизируйте память: для больших наборов данных и широкого диапазона символов используйте компактные структуры или хеш-таблицы.
Итак, алгоритм Counting Sort при правильной настройке и подготовке данных — это мощный инструмент для быстрого и стабильного сортирования строк по фиксированному признаку. Он отлично подходит для задач, где объем данных недостаточно велик, чтобы оправдать использование более сложных алгоритмов, или когда требуется высокая скорость обмена данными по определенному признаку.
Практически, этот метод широко применяется при сортировке слов в словарях, обработке текстовых файлов, организованных по алфавиту, а также в различных задачах анализа данных и машинного обучения, где важна скорость обработки и стабильность порядка.
Обобщенные рекомендации по использованию Counting Sort для строк
Если вы планируете внедрять Counting Sort в реальные проекты, не забудьте о следующих важных моментах:
- Обязательно анализируйте максимальный диапазон символов — чтобы снизить объем массива подсчета.
- Используйте для подготовки строк стандартные методы нормализации текста.
- Для больших данных комбинируйте Counting Sort с другими алгоритмами — например, Radix Sort или MSD sort.
- Обеспечьте защиту от ошибок при обработке некорректных или неоднородных данных.
Вопрос-ответ: что спрашивают про Counting Sort для строк?
Вопрос: Можно ли использовать Counting Sort для сортировки очень длинных строк, например, документов или текстов на нескольких страницах?
Ответ: Использование Counting Sort для очень длинных строк или больших текстовых документов не является оптимальным решением. Алгоритм требует создания массива подсчета, размеры которого соответствуют диапазону возможных символов. Чем длиннее строки и чем более разнообразный набор символов, тем больше потребуется ресурсов. В таких случаях лучше использовать более универсальные алгоритмы сортировки, например, Radix Sort с поэтапной сортировкой по позициям или специально оптимизированные методы обработки текста. Counting Sort хорош для фиксированных, коротких и ограниченных по диапазону ключевых данных, а для больших текстовых файлов он может быть неэффективен по времени и памяти.
Подробнее
| Запрос 1 | Запрос 2 | Запрос 3 | Запрос 4 | Запрос 5 |
|---|---|---|---|---|
| сортировка строк методом Counting Sort | эффективность Counting Sort для текста | примеры использования Counting Sort | как подготовить строки для сортировки | ограничения Counting Sort на строки |
| алфавит для сортировки строк | можно ли сортировать юникодом | частая реализация Counting Sort | сравнение Counting Sort и Radix Sort | стабильная сортировка строк |
| преимущества Counting Sort для текста | структура данных для сортировки строк | использование в больших данных | подготовка данных к сортировке | проблемы с масштабируемостью |