Советы и методы эффективной сортировки для вычисления медианы
Когда мы сталкиваемся с задачами обработки больших объемов данных, одна из ключевых проблем — правильное и быстрое определение медианы. Медиана, это медианное значение набора чисел, которое разделяет его на две равные по количеству части; В этой статье мы расскажем о различных методах сортировки, которые позволяют эффективно находить медиану, и разберем практические подходы, применяемые в программировании и аналитике данных.
Что такое медиана и зачем она нужна?
Медиана — это статистическая мера, которая показывает срединное значение в наборе данных. В отличие от среднего арифметического, медиана менее чувствительна к выбросам и искажениям, что делает её особенно важной в аналитике, финансовых расчетах и при обработке нерегулярных данных.
Представим, что у нас есть следующий набор чисел:
| Набор данных |
|---|
| 3, 7, 2, 9, 4 |
Для определения медианы нам нужно отсортировать эти числа и выбрать центральное. В случае нечетного количества элементов — это будет среднее число, а при четном — средняя двух центральных чисел.
Пример:
- Нечетный набор: 1, 3, 5 → медиана — 3
- Четный набор: 1, 3, 5, 7 → медиана — (3+5)/2 = 4
Основные алгоритмы сортировки для поиска медианы
Простая сортировка (Bubble Sort, Selection Sort)
Первые методы — это классические алгоритмы сортировки, такие как пузырьковая и выборочная сортировки. Они просты в понимании и реализации, но неэффективны для больших наборов данных, поскольку имеют высокую временную сложность — O(n^2). Тем не менее, для небольших объемов данных эти методы вполне подойдут.
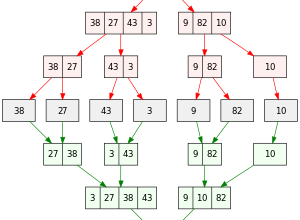
Более эффективные алгоритмы (Merge Sort, Quick Sort)
Для сортировки больших массивов используются более производительные алгоритмы:
- Merge Sort, стабилен и работает за O(n log n).
- Quick Sort — очень быстрый в среднем и также имеет временную сложность O(n log n), хотя в худшем случае — O(n^2).
Эти методы позволяют быстро отсортировать большие объемы данных, что важно при поиске медианы.
Выборочная стратегия (Median of Medians)
Для поиска медианы без полного сортирования данных существует алгоритм Median of Medians, который обеспечивает подбор медианы за время O(n). Этот метод разбивает исходный массив на подмножества, ищет медианы каждого, и затем из них выделяет медиану, которая и есть искомое значение.
| Преимущества | Недостатки |
|---|---|
|
|
Эффективное нахождение медианы в больших данных
Если речь идет об обработке больших объемов данных, полное сортирование становится неэффективным и затратным по времени. В таких случаях применяются алгоритмы выборочного поиска и проблема медианного поиска.
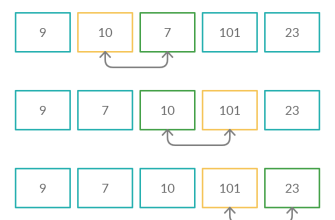
Алгоритм Quickselect
Одним из наиболее популярных методов является Quickselect — алгоритм, основанный на принципе быстрого выбора (QuickSort), но предназначенный для поиска k-го по порядку элемента, например, медианы.
- Работает за среднее время O(n).
- Проводит частичное сортирование, находя нужный элемент без полной сортировки массива.
Этот способ особенно хорош для обработки потоковых данных и в реальных приложениях, где важна скорость.
Использование кучи (Heap)
Известный способ — применение двух куч:
- Максимальная куча для меньшей половины данных.
- Минимальная куча для большей половины данных.
Этот метод позволяет динамично обновлять медиану при добавлении новых элементов, что особенно актуально в реальных потоковых системах.
| Метод | Преимущества | Недостатки |
|---|---|---|
| Quickselect | Быстрый, использует меньше памяти | В худшем случае — O(n²), требует аккуратной реализации |
| Две кучи | Подходит для потоковых данных, онлайн расчет | Сложнее в реализации, требует поддержания структур данных |
Практическое применение методов сортировки для нахождения медианы
Рассмотрим практические сценарии, где выбор метода влияет на эффективность работы программных решений. Например, при обработке временных рядов в финансовой аналитике, или при аналитике пользовательских данных в реальном времени.
Кейс: Анализ финансовых потоков
В финансовых системах зачастую необходимо быстро определить медиану значений для выявления трендов и исключения влияния аномалий. В таких случаях предпочтительно использовать алгоритм Quickselect или структуру двух куч, чтобы находить медиану по мере поступления данных без необходимости их полного пересортирования.
Кейс: Обработка потоковых данных
Когда данные поступают в режиме реального времени, важно иметь эффективный механизм для динамического обновления медианы. В таких случаях лучше использовать двоичные кучи, что позволяет вставлять новые значения и быстро пересчитывать медиану с минимальными затратами.
Выбор метода поиска медианы зависит от конкретных условий задачи: объема данных, необходимости онлайн-обработки, требований к скорости и точности. Для небольших наборов данных подойдет простое полное сортирование, однако при работе с большими массивами — предпочтительнее алгоритмы Quickselect или структуры на основе куч. Важным остается учитывать баланс между затратами по времени и сложности реализации.
В реальных проектах зачастую используют комбинацию методов и алгоритмов, чтобы добиться оптимальной производительности. Не стоит забывать и о предварительной обработке данных, которую также важно учитывать при проектировании систем.
"Какой алгоритм сортировки выбрать для нахождения медианы в вашем проекте? — Выбор зависит от размера данных, требований к скорости обработки и наличия ресурсов. Для небольших наборов — простая сортировка. Для больших, алгоритмы Quickselect и структуры с кучами помогут добиться оптимальных результатов."
Вопрос к статье
Какие алгоритмы сортировки наиболее эффективны для быстрого вычисления медианы в больших объемах данных?
Наиболее эффективными для быстрого вычисления медианы в больших объемах данных считаются алгоритмы Quickselect и структуры, основанные на двух кучах. Они обеспечивают низкую временную сложность (O(n) в среднем при правильной реализации) и позволяют динамически обновлять значение медианы без необходимости полного сортирования массива.
Подробнее
| методы сортировки для медианы | эффективные алгоритмы поиска медианы | Quickselect для медиа | использование кучи для медианы | обработка больших данных для медианы |
| алгоритм median of medians | скорость сортировки при определении медианы | оптимизация поиска медианы | медиана в реальном времени | начальные стратегии сортировки |